Posts tagged ‘contextualized computing education’
What Humanities Scholars Want Students To Know About the Internet: Alternative Paths for Alternative Endpoints
After we got the go-ahead to start developing PCAS (see an update on PCAS here), I had meetings with a wide range of liberal arts and sciences faculty. I’d ask faculty how they used computing in their work and what they wanted their students to know about computing. Some faculty had suggested that I talk to history professor, LaKisha Michelle Simmons. I met with her in January 2023, and she changed how I thought about what we were doing in PCAS.
I told her that I’d heard that she built websites to explain history research to the general public, and she stopped me. “No, no —- my students build websites. I don’t built websites.” I asked her what she would like her students to know about the Internet. “I could teach them about how the Internet works with packets and IP addresses. I could explain about servers and domain names.”
She said no. She was less interested in how the Internet worked. She had three specific things she wanted me to teach students.
- She wanted students to know that there are things called databases.
- That databases, if they are designed well, are easy to index and to find information in.
- Databases could be used to automatically generate Web pages.
Her list explains a huge part of the Web, but was completely orthogonal to what I was thinking about teaching. She wasn’t asking me to teach tools. She wanted me to teach fundamental concepts. She wanted students to have understanding about a set of technologies and ideas, and the students really didn’t need IP addresses and packets to understand them.
The important insight for me was that the computing that she was asking for was a reasonable set, but different from what we normally teach. These are advanced CS ideas in most undergraduate programs, typically coming after a lot of data structures and algorithms. From her perspective, these were fundamental ideas. She didn’t see the need for the stuff we normally teach first.
I put learning objectives related to her points on the whiteboards in my participatory design sessions. This showed up in the upper-right hand corner of the Justice class whiteboard — the most important learning objective. LaKisha gave me the learning objectives, and the humanities scholars who advised me supported what she said. This became a top priority for our class Computing’s Impact on Justice: From Text to the Web.

Figuring out how
During the summer of 2022, a PhD student working with me, Tamara Nelson-Fromm, a group of undergraduate assistants, and I worked at figuring out how to achieve these goals. We had to figure out how to have students work with LaKisha’s three learning objectives, without complicated tools. We were committed to having students program and construct things — we didn’t want this to be a lecture and concepts-only class.
We were already planning on using Snap, and it has built-in support for working with CSV files. Undergraduate Fuchun Wang created a great set of blocks explicitly designed to look like SQL for manipulating CSV files. We used these blocks to talk about queries and database design in the class.
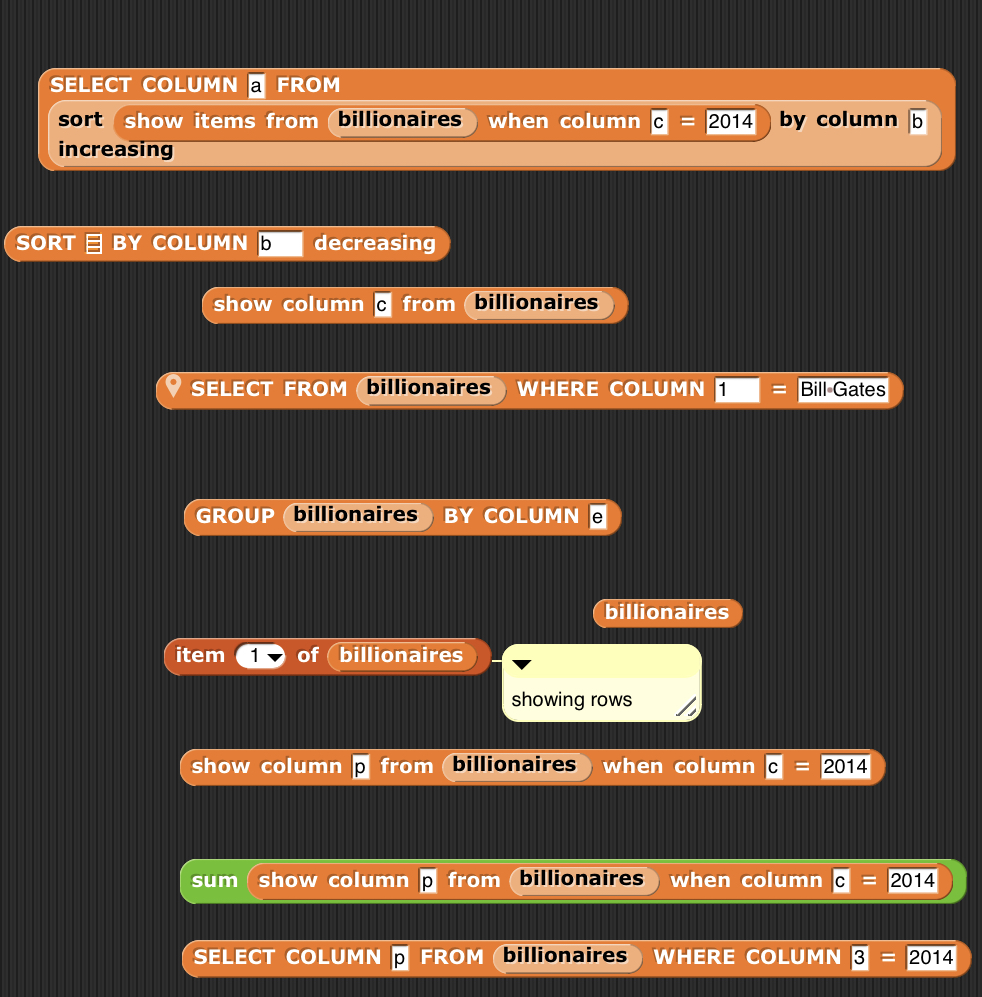
Tamara and I talked a lot about how to make the HTML part work. I had promised our advisors that we would not require LSA students to install anything on their computers in the intro courses. We talked about the possibility of building a teaspoon language for Web page development and for use as templating tool for databases, but I was worried that we were already throwing so many languages at the students.
Then it occurred to us that we could do this all with Snap. We built a set of blocks to represent the structure of an HTML page, like in this example. Since we could define our own control structures in HTML, we could present the pieces of a Web page nested inside other blocks, to mirror the nested structure of the tags.

Those last two blocks were key. The view webpage block displays in the stage the first 50 lines of the input HTML. That’s important so that students see the mapping from blocks to HTML. The open HTML page block opens a browser window and renders the HTML into it. (That was a tricky hack to get working.)
This was enough for us to talk about building Web pages in Snap, viewing the HTML, then rendering the HTML in the browser. Here’s a slide from the class. In deciding what computer science ideas to emphasize, I used the work of Tom Park who studied student errors in HTML and CSS, and found that ideas of hierarchy and encapsulation were a major source of error. Those are important ideas across computing, so I used those as themes across the CS instruction — and the structure we could build in the Snap block helped to present those ideas.
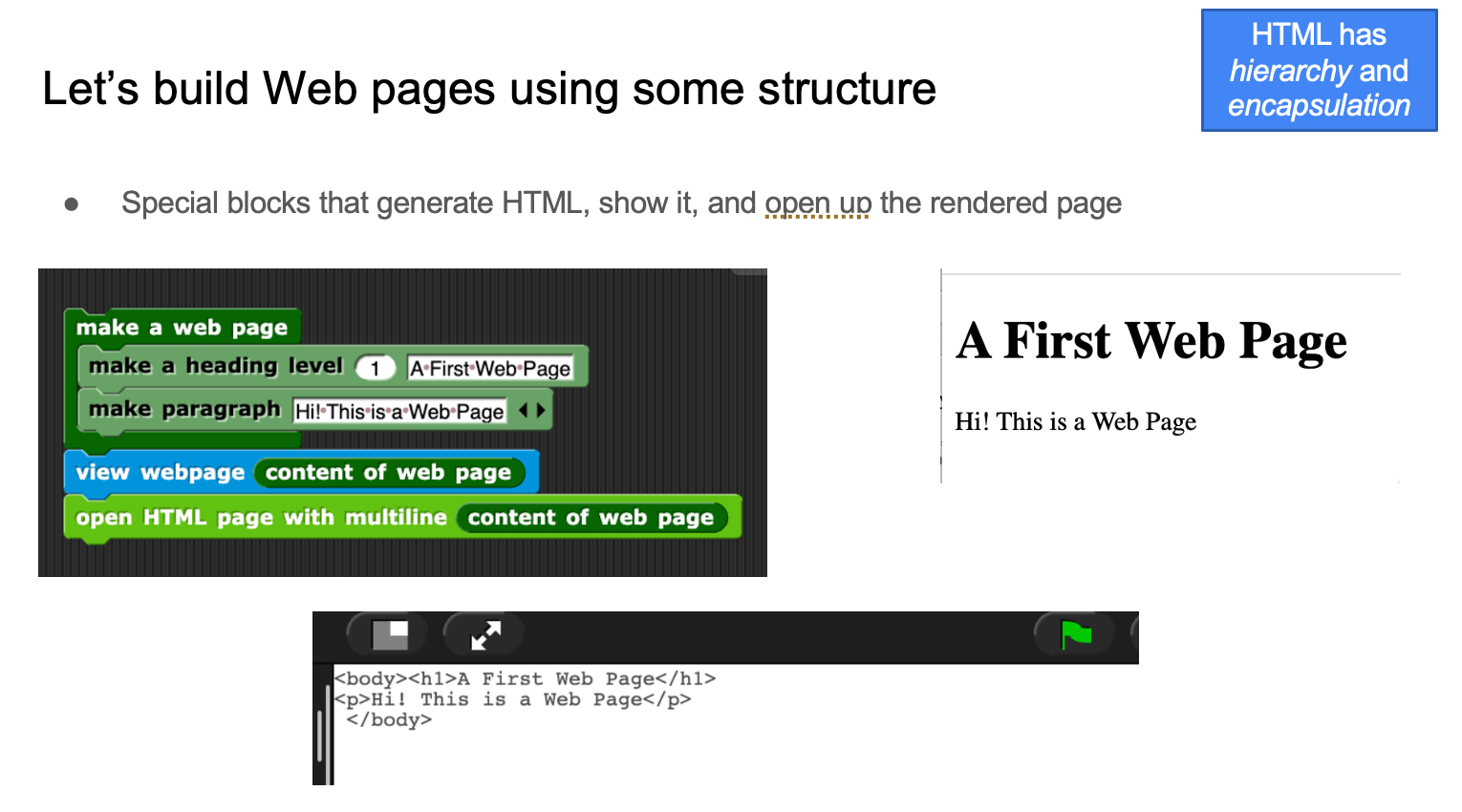
All of that together is enough to build Web pages from database queries. Here’s an example — querying the billionaires database from Forbes for those from Microsoft, then creating a Web page form letter asking them for money.
We use these blocks in both of our classes:
- In the Justice class, students use the HTML blocks to create a resume for a fictional or historical character in a homework assignment. In a bigger project, students design their own database of anything they want, then create two queries. One should return 1-3 items, and should generate a detail page for each of those items. The second query should return several items, and return an overview page for that set of items.
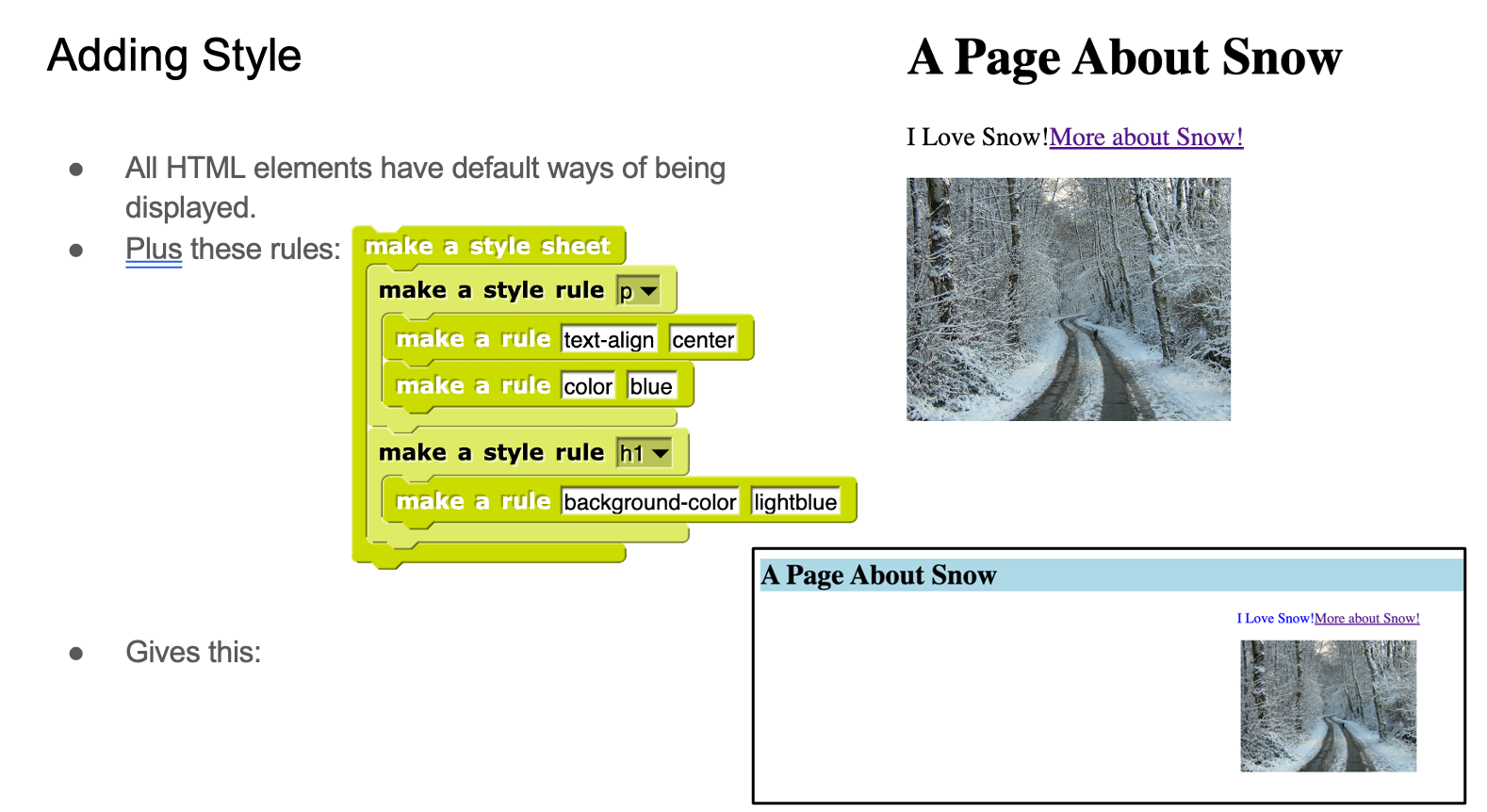
- In the Expression class, building an HTML page is the last homework. They use style rules and have to embed a Snap project so that there’s interactivity in the page. Here’s a slide from the class where we’re showing how adding style rules changes the look-and-feel of an HTML page.
Alternative Paths to Alternative Endpoints
Mike Tissenbaum, David Weintrop, Nathan Holbert, and Tammy Clegg have a paper that I really like called “The case for alternative endpoints in computing education” (BJET link, UIUC repository link). They argue “for why we need more and diverse endpoints to computing education. That many possible endpoints for computing education can be more inclusive, just and equitable than software engineering.” I strongly agree with them, but I learned from this process that there are also alternative paths.
Computer science sequences don’t usually start with databases, HTML, and building web pages from database queries, but that’s what my humanities scholars advisors wanted. Computer science usually starts from algorithms, data structures, and writing robust and secure code, which our scholars did not want. Our PCAS courses are certainly about alternative endpoints — we’re not preparing students to be professional software developers. We’re also showing that we can start from a different place, and introduce “advanced” ideas even in the first class. Computing education isn’t a sequence — it’s a network.
Participatory Design to Set Standards for PCAS Courses
My main activity for the last year has been building two new courses for our new Program in Computing for the Arts and Sciences (PCAS), which I’ve blogged about recently here (with video of a talk about PCAS) and here where I described our launch. Here are the detailed pages describing the courses (e.g., including assignments and examples of students’ work):
- COMPFOR 121: Computing for Creative Expression
- COMPFOR 111: Computing’s Impact on Justice: From Text to the Web
When we got the go-ahead to start developing PCAS last year, the first question was, “Well, what should we teach?” The ACM/IEEE Computing Curriculum volumes weren’t going to be much help. They’re answering the question “What do CS, Software Engineering, Information Technology, etc. majors need to know?” They’re not answering the question, “What do students in liberal arts and sciences need to know about Computing for Discovery, for Expression, and for Justice?”
My starting place was the Computing Education Task Force (CETF) report (see link here) which summarized dozens of hours of interviews and survey results from over 100 faculty. We decided that the first two courses would be on Expression and Justice. There already were classes that introduced programming in a Discovery framing in some places on campus (and my colleague, Gus Evrard, has taken that even farther now — but that’s another blog post). There was nothing for first year students to introduce them to coding in an Expression or Justice context.
When faced with a design problem, I often think “WWBD” — “What Would Betsy Do.” I learned about participatory design working with Betsy DiSalvo at Georgia Tech, and now I reach for those methods often. I created participatory design activities so that Expression and Justice faculty in our College of Literature, Science, and the Arts (LSA) could set the standards for these courses.
I created three Padlets, shared digital whiteboards. A group of people edit a whiteboard, and everyone can see everyone else’s edits.
- One of them was filled with about 20 learning goals derived from the CETF report. These aren’t well-formed learning goals (e.g., not always framed in terms of what students should be able to do). These were what people said when we asked them “What should students in LSA learn about computing?” I wasn’t particularly thorough about this — I just grabbed a bunch that interested me when I reviewed the document and thought about what I might teach.
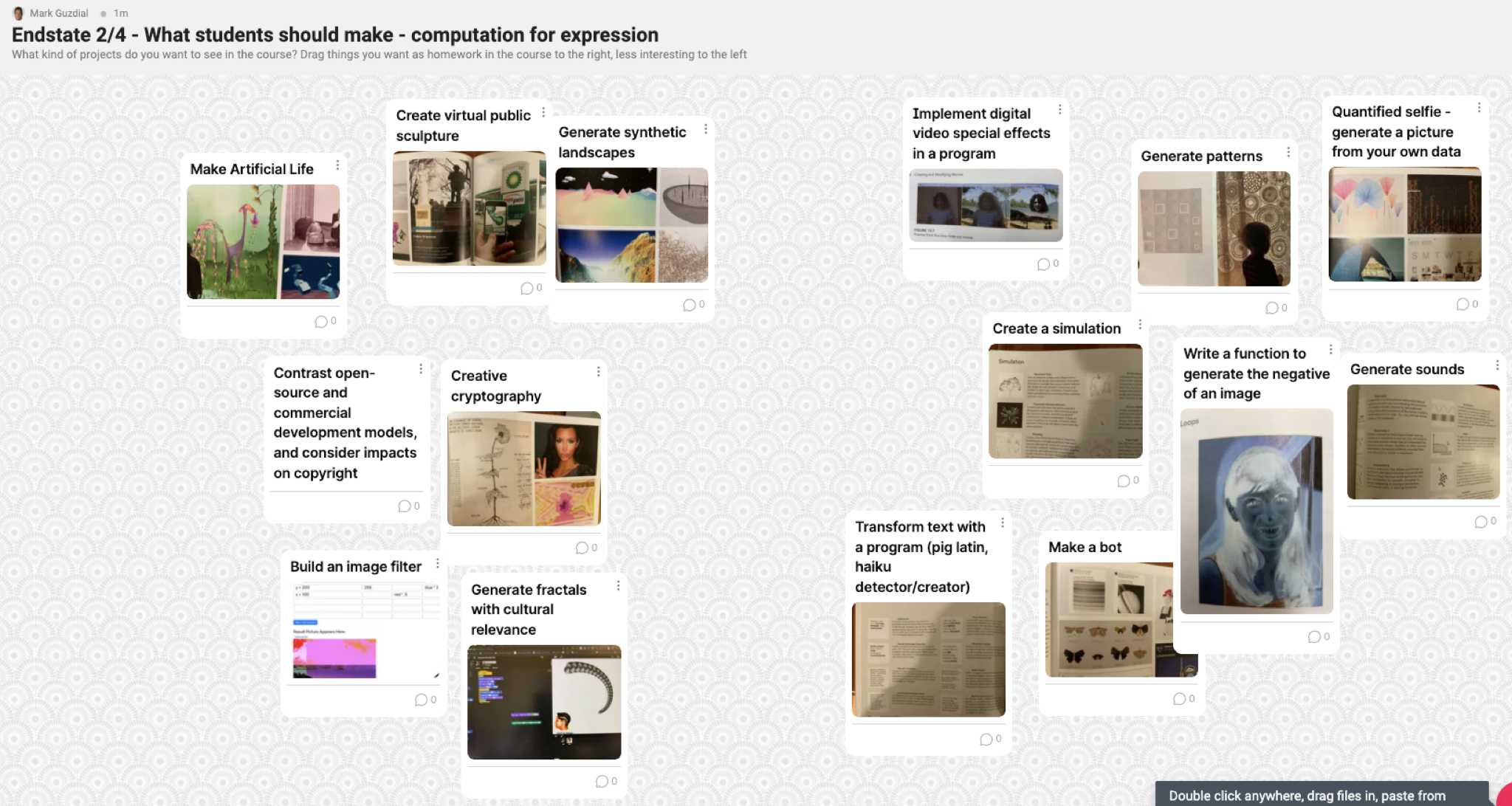
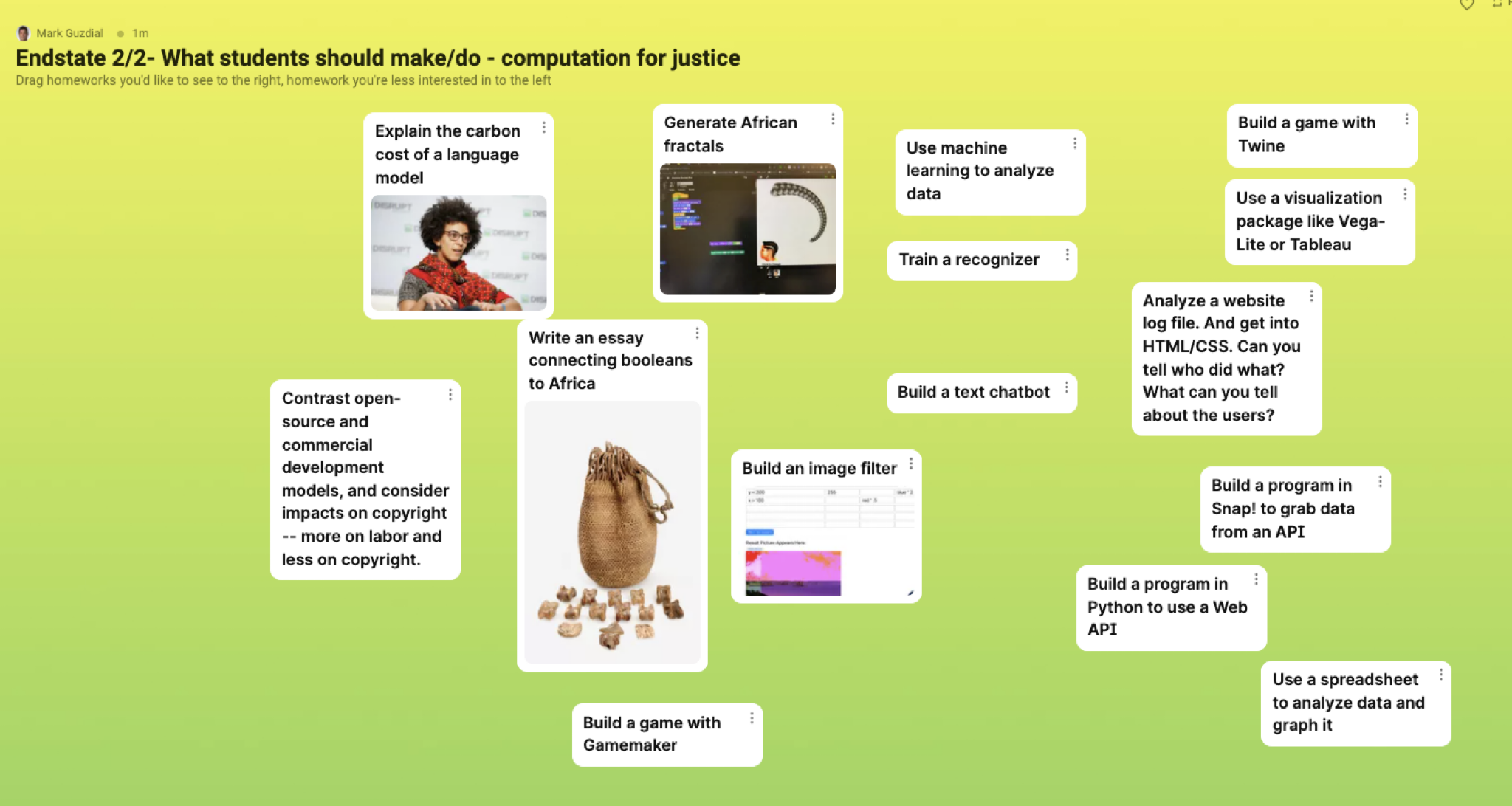
- I created two more Padlets with possible learning activities for students in these classes. Yvette Granata had recommended several books to me on coding in Expression and Justice contexts, so a lot of the project ideas came out of those. These were things that I was actively considering for the courses.
I ran two big sessions (with some 1:1 discussions afterwards with advisors who couldn’t make the big sessions), one for Expression and one for Justice. These were on-line (via Zoom) with me, Aadarsh Padiyath (PhD student working with me and Barbara Ericson), and a set of advisors. The advisors were faculty who self-identified as working in Computing for Expression or Computing for Justice. The design sessions had the same format.
- I gave the advisors a copy of the learning goals Padlet. (Each session started with the same starting position.) I asked them as a group to move to the right those learning goals they wanted in the class and to move to the left those learning goals that they thought were less important. They did this activity over about 20-30 minutes, talking through their rationale and negotiating placement left-to-right.
- I then gave the advisors a copy of the learning activities Padlet. Again, I asked them to sort them right is important and left is less important.. Again, about 20-30 minutes with lots of discussion.
We got transcripts from the discussion, and Aadarsh produced a terrific set of notes from each session. These were my standards for these courses. This guided me in deciding what goes in and what to de-emphasize in the courses.
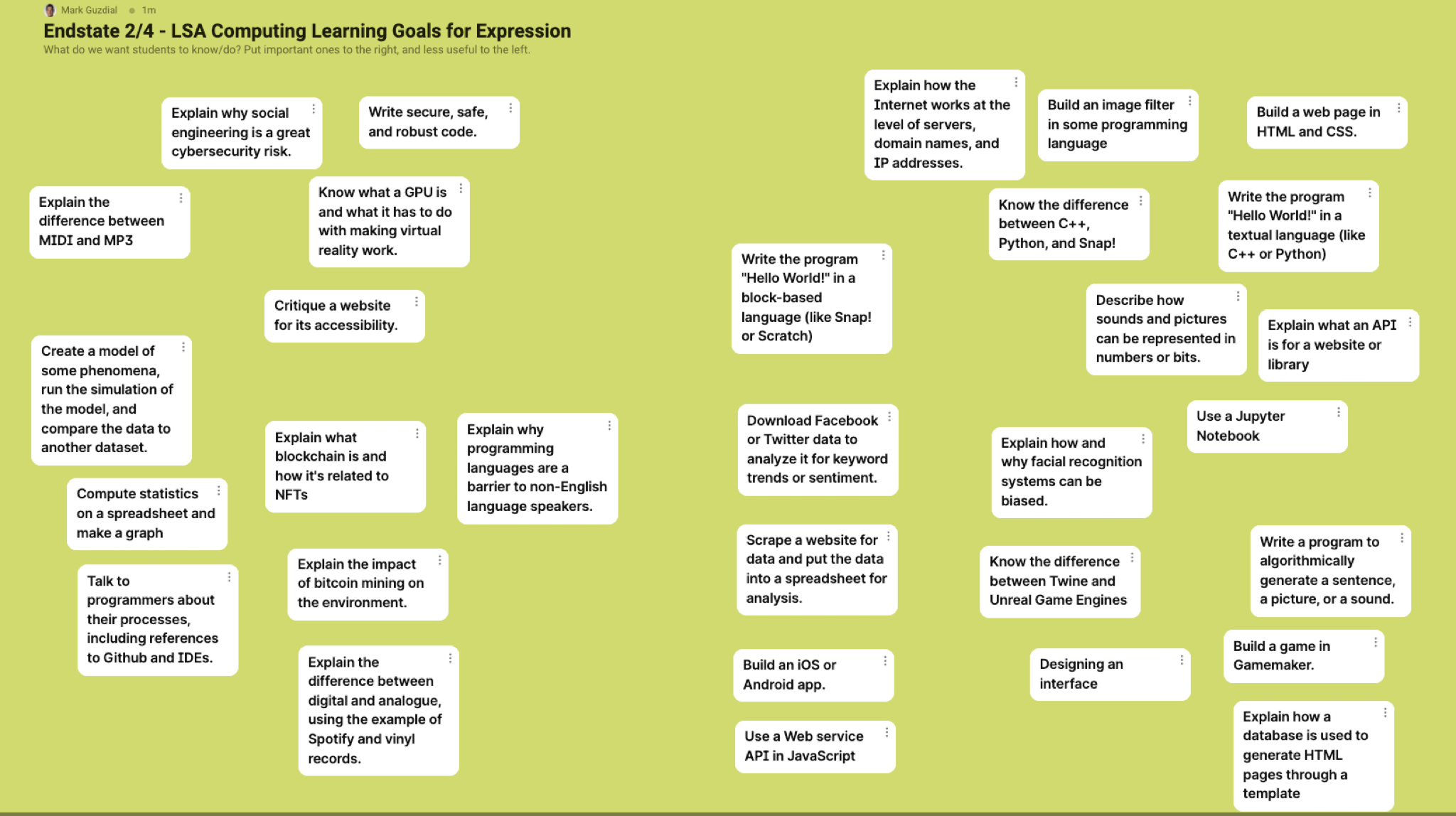
Below are the end states of the shared whiteboards. There’s a lot in here. Three things I find interesting:
- Notice where the computer science goals like “Write secure, safe, and robust code” end up.
- Notice what’s in the upper-right corner — I was surprised in both cases.
- Notice that building chatbots is right-shifted for both Expression and Justice. Today, you’d say “Well, of course! ChatGPT!” But I held these sessions in February of 2022. The classes have a lot about chatbots in them, and that put us in a good place for integrating discussions about LLMSs this last semester.
Expression Learning Goals
(To see the full-res version, right-click/control-click on the picture, and open the image a new tab.)
Justice Learning Goals

Expression – Learning Activities
Justice – Learning Activities
These are Standards
The best description of how I used these whiteboards and the discussion notes is that these are my standards. My advisors said very clearly during the sessions — there are too many learning objectives and activities for one course here. Things on the left are not unimportant. They’re just not as important.. I can’t possibly get to everything on these whiteboards in a single semester class designed for arts and humanities students (as the primary audience) with no programming background and with some hesitancy about mathematics.
My advisors were designing in a vacuum. They weren’t going to actually teach this course. Most of them had never seen a course that tried to achieve these objectives for this student audience. So they told me (for Justice), “Yeah, use Jupyter notebooks, and teach HTML and databases and code, all in one semester. And don’t make students install anything on their computers — do it all in the browser.” But they didn’t really have an idea how this might work, or if it was possible. They also didn’t articulate, “You’ll probably to teach about data and iteration and conditionals in here, too.”
It was my job to use these standards as priorities, cover what I could, and fill in with the computer science knowledge to make these do-able. We are also using these to inform future classes, the next classes we make for PCAS. You can compare these whiteboards back up to the course pages at the top of this post to decide how well we did.
Overall, we use participatory design methods a lot as we design for PCAS, to get the input of faculty outside of CS, because these aren’t computer science classes. They are not CS0, CS1, or CS0.5, all of which presume a linear progression towards the goal of being a CS major. Yes, we’re teaching computer science knowledge and skills, but these are classes in Computing for Expression and Computing for Justice. The faculty in those areas are the authorities in what we should teach. They decide what’s important.
Side note: I’ve had these data for over a year, and even presented some of them in a poster at ITiCSE last year. I have trying to figure out how to share them. Maybe this could have been a peer-reviewed publication (conference or journal)? I don’t know. It’s a design activity, and I learned a lot from it, but I don’t know how to write about it as scholarship. I finally decided to write this blog post so that I could share the whole big Padlet whiteboards. Traditional publication venues would be unlikely to let me put these big pictures out there, but I can in a blog post.
My many thanks to my advisors for these classes: Yvette Granata, Catherine Griffiths, M. Remi Yergeau, Tony Bushner, Justin Schell, Jan Van den Bulck, Justin Joque, Sarita Schoenebeck , Nick Henricksen, Maggie Frye, Anne Cong-Huyen, and Matt Bui
Updates: Workshop on Contextualized Approaches to Introduction to Computing, from the Center for Inclusive Computing at Northeastern University
From Nov 2020 to Nov 2021, I was a Technical Consultant for the Center for Inclusive Computing at Northeastern University, directed by Carla Brodley. (Website here.) CIC works directly with CS departments to create significant improvements in female participation in computer science programs. I’m no longer in the TC role, but I’m still working with CIC and Carla. I’ll be participating in a workshop that they’re running on Monday March 21. I’ll be talking about Media Computation in Python, and probably show some of the things we’re working on for the new classes here at Michigan.
https://www.khoury.northeastern.edu/event/contextual-approaches-to-introduction-to-computing/
Contextual Approaches to Introduction to Computing
Monday 3/21/22, 3pmEST/12pmPST
Moderator: Carla Brodley; Speakers: Valerie Barr, Mark Guzdial, Ben Hescott, Ran Libeskind-Hadas, Jakita Thomas
Brought to you by the Center for Inclusive Computing at Northeastern University
In this 1.5 hour virtual workshop, faculty from five different universities in the U.S. will present their approach to creating and offering an introductory computer science class (CS0 or CS1) for students with no prior exposure to computing. The key differentiator of these approaches is that the introduction is contextualized in one area outside of computing throughout the semester. Using the context of areas such as cooking, business, biology, media arts, and digital humanities, these courses appeal to students across the university and have realized spectacular results for student retention in CS0/CS1, persistence to taking additional CS courses, and declaring a major or minor in computing. The importance of attracting students to computing after they enter university is critical to moving the needle on increasing the demographic diversity of students who graduate in computing. Interdisciplinary introductory computing classes provide a pathway to students discovering and enjoying computing after they start university. They also help students with no prior coding experience gain familiarity with computing before taking additional courses required for the CS major. The workshop will begin with a short presentation by each faculty member on their approach to contextualized CS0/CS1 and will touch upon the university politics involved in its creation, the curriculum, and the outcomes. We will then split into smaller breakout sessions five times to enable participants to meet with each of the five presenters for questions and more in-depth conversations.
Is Liveness a critical factor in learning Computer Science? Context, motivation, and feedback for learning programming
My CACM Blog post for November is on the topic of Direct Instruction, why it’s better than Discovery Learning, and how we should teach programming “directly.”
I wonder about the limitations of Direct Instruction. I don’t think everything can be learned with direct instruction, even with deliberate practice.
At SIGCSE 2016, John Sweller made a provocative claim (that I haven’t yet found in his published papers). He said that humans must be able to learn higher-order thinking skills. We’d be dead if we didn’t. However, we cannot teach them. Students have to figure them out from experience. Is programming a similar kind of task?
I have been studying Spanish on a streak of over 600 days in DuoLingo now. DuoLingo is the best direct instruction I’ve ever had. Everything I do is deliberate practice — it’s really good at figuring out what I’m not good at, and giving me more problems on that. I am nowhere near fluent. I know some words. I can read some. I’m getting better at hearing. I am not fluent. Maybe learning natural and programming languages both require more than direct instruction.
What leads to fluency, in natural languages or programming languages? I suspect that part of it is context and motivation. You have to be in a position to want to say something (in a natural or programming language) in order to learn it.
But I also think it’s about feedback. I don’t really learn Spanish well because I’m rarely in a position to use it. If I did, I’d get a response to what I said. Can anyone learn to program without trying to write some code and getting feedback on whether it works? The issue of feedback came up several times in the recent discussion about the relationship between teaching programming and teaching composition.
Steven Tanimoto talks about the value of “liveness” in a programming environment (see paper here), which is about the ease of writing code and getting different kinds of feedback on the code. Maybe Liveness encapsulates the kinds of things we need for successful CS learning. Of course, even “liveness” doesn’t give the kind of feedback that a human reader can, but it does shorten the feedback timing loop.
Designing for Wide Walls with Contextualized Computing Education
Nice blog post from Mitchel. The wide walls metaphor is an argument for contextualized computing education. Computing is a literacy, and we have to offer a variety of genres and purposes to engage students.
But the most important lesson that I learned from Seymour isn’t captured in the low-floor/high-ceiling metaphor. For a more complete picture, we need to add an extra dimension: wide walls. It’s not enough to provide a single path from low floor to high ceiling; we need to provide wide walls so that kids can explore multiple pathways from floor to ceiling.Why are wide walls important? We know that kids will become most engaged, and learn the most, when they are working on projects that are personally meaningful to them. But no single project will be meaningful to all kids. So if we want to engage all kids—from many different backgrounds, with many different interests—we need to support a wide diversity of pathways and projects.
Source: Mitchel Resnick: Designing for Wide Walls | Design.blog
The Future of Computing Education is beyond CS majors: Report from Snowbird #CSforAll
Last week, I attended the Computing Research Association (CRA) Snowbird conference of deans and chairs of computing. (See agenda here with slides linked.) I presented on a panel on why CS departments should embrace computing education research, and another on what CS departments can do to support the CS for All initiative. I talked in that second session about the leadership role that universities can play in creating state partnerships and influencing state policy (see the handout for my discussion table).
Amy Ko was in both sessions with me, and she’s already written up a blog post about her experiences, which match mine closely (including the feeling of being an imposter). I recommend reading her post.
Here, I’m sharing a key insight I saw and learned at Snowbird. Before the conference even started, our Senior Associate Dean for the College of Computing, Charles Isbell, challenged me to name another field that is overwhelmed with majors AND offers service courses to so many other majors. (Maybe biology because of pre-meds?) Computer Science is increasingly the provider of courses to non-CS majors, and those majors want something different than CS majors.
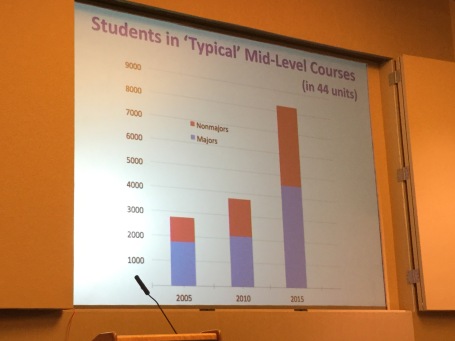
The morning of the first day was dedicated to the enrollment surge. CRA has been gathering data at many institutions on the surge, and Tracy Camp did a great job presenting some of the results. (Her slides are now available here, so you don’t have to rely on my pictures of her slides.) Here’s the bottomline: Student growth has been enormous (across different types of institutions), without a matching growth in faculty. The workload is increasing.

But here’s the surprise: Much of the growth in course enrollment is not CS majors. A large percentage of the growth is in other majors taking CS classes. The below graph is for “mid-level” CS courses, and there are similar patterns in intro and upper-level courses.
Tracy also presented a survey of students (slides available here), which was really fascinating. Below is a survey of (a lot) of intro students at several institutions. All the differences described are significant at p<0.05 (not 0.5 as it says). The difference in what non-majors want and CS majors was is interesting. Majors want (significantly more than non-majors) to “make a lot of money.” Non-majors more significantly want to “Give back to my community” and “Take time off work to care for family.”

U. Illinois has the most innovative program I have heard of for meeting these new needs. They are creating a range of CS+X degree programs. First, these CS+X programs are significant parts of the “X” departments.

But these stats blew me away: CS+X is now 30% of all of CS at U. Illinois (which is a top-5 CS department), and 50% of all admitted first years this year! And it’s 28% female.

It’s pretty clear to me that the future of computing education is as much about providing service to other departments as it is about our own CS major. We have suspected that the growth is in the non-majors for awhile, but now we have empirical evidence. I’ve been promoting the idea of contextualized-computing education, and the notion that other majors need a different kind of CS than what CS majors need. We need to take serious the education of non-CS majors in Computer Science.
Blog Post #1999: The Georgia Tech School of Computing Education #CSEdWeek
Three and a half years, and 1000 blog posts ago, I wrote my 999th blog post about research questions in computing education (see post here). I just recently wrote a blog post offering my students’ take on research questions in computing education (see post here), which serves to update the previous post. In this blog post, I’m going to go more meta.
In my CS Education Research class (see description here), my students read a lot of work by me and my students, some work on EarSketch by Brian Magerko and Jason Freeman, and some by Betsy DiSalvo. There are other researchers doing work related to computing education in the College of Computing at Georgia Tech, notably John Stasko’s work on algorithm visualization, Jim Foley’s work on flipped classrooms (predating MOOCs by several years), and David Joyner and Ashok Goel’s work on knowledge-based AI in flipped and MOOC classrooms, and my students know some of this work. I posed the question to my students:
If you were going to characterize the Georgia Tech school of thought in computing education, how would you describe it?
We talked some about the contrasts. Work at CMU emphasizes cognitive science and cognitive tutoring technologies. Work at the MIT Media Lab is constructionist-based.

Below is my interpretation of what I wrote on the board as they called out comments.
- Contextualization. The Georgia Tech School of Computing education emphasizes learning computing in the context of an application domain or non-CS discipline.
- Beyond average, white male. We are less interested in supporting the current majority learner in CS.
- Targeted interventions. Georgia Tech computing education researchers create interventions with particular expectations or hypotheses. We want to attract this kind of learner. We aim to improve learning, or we aim to improve retention. We make public bets before we try something.
- Broader community. Our goal is to have a broaden participation in computing, to extend the reach of computer science.
- We are less interested in making good CS students better. To use an analogy, we are not about raising the ceiling. We’re about pushing back the walls and lowering the floors, and sometimes, creating whole new adjacent buildings.
- We draw on learning sciences theory, which includes cognitive science and educational psychology (e.g., cognitive load theory).
- We draw on social theories, especially distributed cognition, situated learning, social cognitive theory (e.g., expectancy-value theory, self-efficacy).
I might have spent hours coming up with a list like this, but in ten minutes, my students came up with a good characterization of what constitutes the Georgia Tech School of Thought in Computing Education.
Why the Maker Movement is important for Schools: Outside the Skinner Box
I liked Gary Stager’s argument in the post below about what’s important about the Maker Movement for schools: it’s authentic in a physical way, and it contextualizes mathematics and computing in an artistic setting.
For too long, models, simulations, and rhetoric limited schools to abstraction. Schools embracing the energy, tools, and passion of the Maker Movement recognize that, for the first time in history, kids can make real things – and, as a result, their learning is that much more authentic. Best of all, these new technologies carry the seeds of education reform dreamed of for a century. Seymour Papert said that John Dewey’s educational vision was sound but impossible with the technology of his day. In the early- to mid-20th century, the humanities could be taught in a project-based, hands-on fashion, but the technology would not afford similarly authentic opportunities in mathematics, science, and engineering. This is no longer the case.
Increasingly affordable 3-D printers, laser cutters, and computer numerical control (CNC) machines allow laypeople to design and produce real objects on their computers. The revolution is not in having seventh-graders 3-D print identical Yoda key chains, but in providing children with access to the Z-axis for the first time. Usable 3-D design software allows students to engage with powerful mathematical ideas while producing an aesthetically pleasing artifact. Most important, the emerging fabrication technologies point to a day when we will use technology to produce the objects we need to solve specific problems.
Coding the Curriculum: How High Schools Are Reprogramming Their Classes
I’d love to see more detail on what they’re doing. It’s what Seymour Papert wanted for Logo, now happening not far from MIT and the original Logo experiments. I love what they say later in the piece about the goal being computing for creativity and calculation, not to become a professional software developer.
It’s a new, albeit eccentric experiment. The school isn’t launching mandatory programming courses into the schedule, exactly, but is instead having its teachers introduce coding (ideally, in the most organic ways possible) into their respective subjects. Calculation-heavy courses such as math and science, as well as humanities such as English, Spanish and history — even theater and music — will all be getting a coded upgrade.
True, Beaver may be the first of its kind to experiment with coding in every class, but the idea that more high school students should take STEM-related courses — particularly in programming and coding — isn’t new.
via Coding the Curriculum: How High Schools Are Reprogramming Their Classes.
Live coding as a path to music education — and maybe computing, too
We have talked here before about the use of computing to teach physics and the use of Logo to teach a wide range of topics. Live coding raises another fascinating possibility: Using coding to teach music.
There’s a wonderful video by Chris Ford introducing a range of music theory ideas through the use of Clojure and Sam Aaron’s Overtone library. (The video is not embeddable, so you’ll have to click the link to see it.) I highly recommend it. It uses Clojure notation to move from sine waves, through creating different instruments, through scales, to canon forms. I’ve used Lisp and Scheme, but I don’t know Clojure, and I still learned a lot from this.
I looked up the Georgia Performance Standards for Music. Some of the standards include a large collection of music ideas, like this:
Describe similarities and differences in the terminology of the subject matter between music and other subject areas including: color, movement, expression, style, symmetry, form, interpretation, texture, harmony, patterns and sequence, repetition, texts and lyrics, meter, wave and sound production, timbre, frequency of pitch, volume, acoustics, physiology and anatomy, technology, history, and culture, etc.
Several of these ideas appear in Chris Ford’s 40 minute video. Many other musical ideas could be introduced through code. (We’re probably talking about music programming, rather than live coding — exploring all of these under the pressure of real-time performance is probably more than we need or want.) Could these ideas be made more constructionist through code (i.e., letting students build music and play with these ideas) than through learning an instrument well enough to explore the ideas? Learning an instrument is clearly valuable (and is part of these standards), but perhaps more could be learned and explored through code.
The general form of this idea is “STEAM” — STEM + Art. There is a growing community suggesting that we need to teach students about art and design, as well as STEM. Here, I am asking the question: Is Art an avenue for productively introducing STEM ideas?
The even more general form of this idea dates back to Seymour Papert’s ideas about computing across the curriculum. Seymour believed that computing was a powerful literacy to use in learning science and mathematics — and explicitly, music, too. At a more practical level, one of the questions raised at Dagstuhl was this: We’re not having great success getting computing into STEM. Is Art more amenable to accepting computing as a medium? Is music and art the way to get computing taught in schools? The argument I’m making here is, we can use computing to achieve math education goals. Maybe computing education goals, too.
Teaching intro CS and programming by way of scientific data analysis
This class sounds cool and similar to our “Computational Freakonomics” course, but at the data analysis stage rather than the statistics stage. I found that Allen Downey has taught another, also similar course “Think Stats” which dives into the algorithms behind the statistics. It’s an interesting set of classes that focus on relevance and introducing computing through a real-world data context.
The most unique feature of our class is that every assignment (after the first, which introduces Python basics) uses real-world data: DNA files straight out of a sequencer, measurements of ocean characteristics (salinity, chemical concentrations) and plankton biodiversity, social networking connections and messages, election returns, economic reports, etc. Whereas many classes explain that programming will be useful in the real world or give simplistic problems with a flavor of scientific analysis, we are not aware of other classes taught from a computer science perspective that use real-world datasets. (But, perhaps such exist; we would be happy to learn about them.)
Report on “Computational Freakonomics” Class: Olympics, game consoles, the Euro, and Facebook
I’ve told you a bit about how the Media Computation class went this summer, with the new things that I tried. Let me tell you something about how the “Computational Freakonomics” (CompFreak) class went.
The CompFreak class wasn’t new. Richard Catrambone and I taught it once in 2006. But we’ve never taught it since then, and I’d never taught it before on my own, so it was “new” for me. There were six weeks in the term at Oxford. Each week was roughly the same:
- On Monday, we discussed a chapter from the “Freakonomics” book.
- We then discussed social science issues related to that chapter, from the nature of science, through t-tests and ANOVA, up to multiple linear regression. Sometimes, we did a debate about issues in the chapter (e.g., on “Atlanta is a crime-ridden city” and on “Roe v. Wade is the most significant explanation for the drop in crime in the 1990’s.”)
- Then I showed them how to implement the methods in SciPy to do real analysis of some Internet-based data sets. I give them a bunch of example data sets, and show them how to read data from flat text files and from CSV files.
At the end of the course, students do a project where they ask a question, any question they want from any database. Then, they do it again, but in pair, after a bunch of feedback from me (both on the first project, and on their proposal for the final project). The idea is that the final projects are better than the first round, since they get feedback and combine efforts in the pair. And they were.
- One team looked at the so-called “medal slump” after a country hosts the Olympics. The “medal slump” got mentioned in some UK newspapers this summer. One member of the team had found in his first project that, indeed, the host country wins a statistically significant fewer medals in the following year. But as a pair of students, they found that there was no medal “slump.” Instead, during the Olympics of hosting, there was a huge medal “bump”! When hosting, the country gets more medals, but the prior two and following two Olympics all follow the same trends in terms of medals won.
- Another team looked at Eurozone countries and how their GDP changes tracked one another after moving to the Euro, then tried to explain that in terms of monetary policy and internal trading. It is this case that Eurozone countries who did move to the Euro found that their GDP started correlating with one another, much more than with non-Euro Eurozone countries or with other countries of similar GDP size. But the team couldn’t figure out a good explanation for why, e.g., was it because internal trading was facilitated, or because of joint monetary policy, or something else?
- One team figured out the Facebook API (which they said was awful) and looked at different company’s “likes” versus their stock price over time. Strongly correlated, but “likes” are basically linear — almost nobody un-likes a company. Since stock prices generally rise, it’s a clear correlation, but not meaningful.
- Another team looked at the impact of new consoles on the video game market. Video game consoles are a huge hit on the stock price of the developing company in the year of release, while the game manufacturers stock rises dramatically. But the team realized a weakness of their study: They looked at the year of a console’s release. The real benefit of a new console is in the long lifespan. The year that the PS3 came out, it was outsold by the PS2. But that’s hard to see in stock prices.
- The last team looked at impact of Olympics on the host country’s GDP. No correlation at all between hosting and changes in GDP. Olympics is a big deal, but it’s still a small drop in the overall country’s economy.
One of my favorite observations from their presentations: Their honesty. Most of the groups found nothing significant, or they got it wrong — and they all admitted that. Maybe it was because it was a class context, versus a tenure-race-influenced conference. They had a wonderful honesty about what they found and what they didn’t.
I’ve posted the syllabus, course notes, slides that I used (Richard never used PowerPoint, but I needed PowerPoint to prop up my efforts to be Richard), and the final exam that I used on the CompFreak Swiki. I also posted the student course-instructor opinion survey results, which are interesting to read in terms of what didn’t work.
- Clearly, I was no Richard Catrambone. Richard is known around campus for how well he explains statistics, and I learned a lot from listening to his lectures in 2006. Students found my discussion of inferential statistics to be the most boring part.
- They wanted more in-class coding! I had them code in-class every week. After each new test I showed them (correlation, t-test, ANOVA, etc.), I made them code it in pairs (with any data they wanted), and then we all discussed what they found in the last five minutes of class. I felt guilty that they were just programming away while I worked with pairs that had questions or read email. I guess they liked that part and wanted more.
- I get credit from the students for something that Richard taught me to do. Richard pointed out that his reading of cognitive overload suggests that nobody can pay attention for 90 minutes straight. Our classes were 90 minutes a day, four days a week. In a 90 minute class, I made them get up halfway through and go outside (when it wasn’t raining). They liked that part.
- Students did learn more about computing, inspired by the questions that they were trying to answer. They talk in their survey comments about studying more Python on their own and wishing I’d covered more Python and computing.
- In general, though, they seemed to like the class, and encourage us to offer it on-campus, which we’ve not yet done.
Students who talked to me about the class at the end said that they found it interesting to use statistics for something. Turns out that I happened to get a bunch of students who had taken a lot of statistics before (e.g., high school AP Statistics). But they still liked the class because (a) the coding and (b) applying statistics to real datasets. My students asked all kinds of questions, from what factors influenced money earned by golf pros, to the influences on attendance at Braves games (unemployment is much more significant than how much the team is in contention for the playoffs). One of the other more interesting findings for me: GPD correlates strongly and significantly with number of Olympic gold medals that a country wins, i.e., rich countries win more medals. However, GPD-per-capita has almost no correlation. One interpretation: To win in the Olympics, you need lots of rich people (vs. a large middle class).
Anyway, I still don’t know if we’ll ever offer this class again, on-campus or study-abroad. It was great fun to teach. It’s particularly fun for me as an exploration of other contexts in contextualized computing education. This isn’t robotics or video games. This is “studying the world, computationally and quantitatively” as a reason for learning more about computing.
CalArts Awarded National Science Foundation Grant to Teach Computer Science through the Arts | CalArts
Boy, do I want to learn more about this! Chuck and Processing, and two semesters — it sounds like Media Computation on steroids!
The National Science Foundation (NSF) has awarded California Institute of the Arts (CalArts) a grant of $111,881 to develop a STEM (Science, Technology, Engineering and Mathematics) curriculum for undergraduate students across the Institute’s diverse arts disciplines. The two-semester curriculum is designed to teach essential computer science skills to beginners. Classes will begin in Fall 2012 and are open to students in CalArts’ six schools—Art, Critical Studies, Dance, Film/Video, Music and Theater.
This innovative arts-centered approach to teaching computer science—developed by Ajay Kapur, Associate Dean of Research and Development in Digital Arts, and Permanent Visiting Lecturer Perry R. Cook, founder of the Princeton University Sound Lab—offers a model for teaching that can be replicated at other arts institutions and extended to students in similar non-traditional STEM contexts.
How can we teach multiple CS1’s?
A common question I get about contextualized approaches to CS1 is: “How can we possibly offer more than one introductory course with our few teachers?” Valerie Barr has a nice paper in the recent Journal of Computing Sciences in Schools where she explains how her small department was able to offer multiple CS1’s, and the positive impact it had on their enrollment.
The department currently has 6 full time faculty members, and a 6 course per year teaching load. Each introductory course is taught studio style, with integrated lecture and hands-on work. The old CS1 had a separate lab session and counted as 1.5 courses of teaching load. Now the introductory courses (except Programming for Engineers) continue this model, meet the additional time and count as 1.5 courses for the faculty member, allowing substantial time for hands-on activities. Each section is capped at 18 students and taught in a computer lab in order to facilitate the transition between lecture and hands-on work.
In order to make room in the course schedule for the increased number of CS1 offerings, the department eliminated the old CS0 course. A number of additional changes were made in order to accommodate the new approach to the introductory CS curriculum: reduction of the number of proscribed courses for the major from 8 (out of 10) to 5 (this has the added benefit, by increasing the number of electives, of giving students more flexibility and choice within the general guidelines of the major); put elective courses on a rotation schedule so that each one is taught every other or every third year; made available to students a 4-year schedule of offerings so that they can plan according to the course rotation.
A CS Emporium would be wonderful idea: Efficient and Tailored Computing Education
Over the weekend, I read a post by GasStationsWithoutPumps on speeding through college. The Washington Post has a great article about Virginia Tech’s Math Emporium that provides a mechanism to do that: Self-paced mathematics instruction, with human instructors available for one-on-one help. It’s efficient, and it provides student learning at their pace. I would love to see a computer science version of this. In particular, it would be great if students could explore problems in a variety of contexts (from media to games to robotics to interactive fiction), and get the time in that they need to develop some skill and proficiency. Like the distance education efforts, this is about improving the efficiency of higher education. Unlike distance education, the Emporium includes 1:1 human interaction and the potential for individualized approaches and curriculum. And there’s potential synergy: the content needed to make a CS Emporium work could also be used in a distance education. Here’s my prediction: Without the 1:1 help, I’d expect the distance folks to still have a higher WFD rate.
No academic initiative has delivered more handsomely on the oft-stated promise of efficiency-via-technology in higher education, said Carol Twigg, president of the National Center for Academic Transformation, a nonprofit that studies technological innovations to improve learning and reduce cost. She calls the Emporium “a solution to the math problem” in colleges.
It may be an idea whose time has come. Since its creation in 1997, the Emporium model has spread to the universities of Alabama and Idaho (in 2000) and to Louisiana State University (in 2004). Interest has swelled as of late; Twigg says the Emporium has been adopted by about 100 schools. This academic year, Emporium-style math arrived at Montgomery College in Maryland and Northern Virginia Community College.
“How could computers not change mathematics?” said Peter Haskell, math department chairman at Virginia Tech. “How could they not change higher education? They’ve changed everything else.”
Emporium courses include pre-calculus, calculus, trigonometry and geometry, subjects taken mostly by freshmen to satisfy math requirements. The format seems to work best in subjects that stress skill development — such as solving problems over and over. Computer-led lessons show promise for remedial English instruction and perhaps foreign language, Twigg said. Machines will never replace humans in poetry seminars.
via At Virginia Tech, computers help solve a math class problem – The Washington Post.

Recent Comments