Posts tagged ‘BPC’
Ruthe Farmer’s important big idea: The Last Mile Education Fund to increase diversity in STEM
I met Ruthe Farmer (Wikipedia page) when she represented the Girl Scouts in the early days of the NSF Broadening Participation in Computing (BPC) alliances. She played a significant role in NCWIT. I had many opportunities to interact with her in her roles at NCWIT and CSforAll. Ruthe organized the White House summit with ECEP in 2016 (see blog post) when she was with the Office of Science and Technology Policy in the Obama administration. Her latest project may be the one that’s closest to my heart.
Ruthe has founded and is CEO of the Last Mile Education Fund. Their mission is:
The Last Mile Education Fund offers a disruptive approach to increasing diversity in tech and engineering fields by addressing critical gaps in financial support for low-income underrepresented students within four semesters of graduation.
I was still at Georgia Tech when I heard about the completion microgrant program at Georgia State. Georgia State was (and still is) making headlines for their use of big data to boost retention and get students graduated. Georgia State is the kind of institution where over half of their students are classified as low-income. There is a huge social benefit when GSU can improve their retention statistics. The completion grant program was started in 2011 and focuses on students who could graduate (e.g., their grades were fine), but they had run out of money before they finished. The grant program gave no more than $2,500 per student (Inside Higher Education article). Today, we know that the average grant has actually been $900. That’s a shockingly low cost for getting students the rest of the way to their college degree. It’s a great idea, and deserves to be applied more broadly than one university.
The Last Mile Education Fund especially focuses on getting students from diverse backgrounds into STEM careers. These last gaps in funding are among the barriers that keep girls out from STEM careers (where Ruthe’s focus was in the Girl Scouts and NCWIT) but also low-income students and people of color.
I was reminded to write about the Last Mile Education Fund by Alfred Thompson’s blog (see post here). He’s got a lot more information about the Last Mile Education Fund there.
I am a first generation graduate. My parents and I had no idea how to even apply to college. I am forever grateful that Wayne State University found me in my high school, guided me to applying, and gave me a scholarship to attend. I’m a privileged white guy. Not everybody gets the opportunities I had. It’s critical to extend the opportunity of a higher education degree to a broader and more diverse audience.
The Last Mile Education Fund is important for closing the gap for students from diverse backgrounds. I’m a monthly supporter, and I encourage you to consider giving, too.
Updates: Workshop on Contextualized Approaches to Introduction to Computing, from the Center for Inclusive Computing at Northeastern University
From Nov 2020 to Nov 2021, I was a Technical Consultant for the Center for Inclusive Computing at Northeastern University, directed by Carla Brodley. (Website here.) CIC works directly with CS departments to create significant improvements in female participation in computer science programs. I’m no longer in the TC role, but I’m still working with CIC and Carla. I’ll be participating in a workshop that they’re running on Monday March 21. I’ll be talking about Media Computation in Python, and probably show some of the things we’re working on for the new classes here at Michigan.
https://www.khoury.northeastern.edu/event/contextual-approaches-to-introduction-to-computing/
Contextual Approaches to Introduction to Computing
Monday 3/21/22, 3pmEST/12pmPST
Moderator: Carla Brodley; Speakers: Valerie Barr, Mark Guzdial, Ben Hescott, Ran Libeskind-Hadas, Jakita Thomas
Brought to you by the Center for Inclusive Computing at Northeastern University
In this 1.5 hour virtual workshop, faculty from five different universities in the U.S. will present their approach to creating and offering an introductory computer science class (CS0 or CS1) for students with no prior exposure to computing. The key differentiator of these approaches is that the introduction is contextualized in one area outside of computing throughout the semester. Using the context of areas such as cooking, business, biology, media arts, and digital humanities, these courses appeal to students across the university and have realized spectacular results for student retention in CS0/CS1, persistence to taking additional CS courses, and declaring a major or minor in computing. The importance of attracting students to computing after they enter university is critical to moving the needle on increasing the demographic diversity of students who graduate in computing. Interdisciplinary introductory computing classes provide a pathway to students discovering and enjoying computing after they start university. They also help students with no prior coding experience gain familiarity with computing before taking additional courses required for the CS major. The workshop will begin with a short presentation by each faculty member on their approach to contextualized CS0/CS1 and will touch upon the university politics involved in its creation, the curriculum, and the outcomes. We will then split into smaller breakout sessions five times to enable participants to meet with each of the five presenters for questions and more in-depth conversations.
ICER 2021 Preview: The Challenges of Validated Assessments, Developing Rich Conceptualizations, and Understanding Interest #icer2021
The International Computing Education Research Conference (ICER) 2021 is this week (website here). It should have been in Charleston, South Carolina (one of my favorite cities), but it will instead be all on-line. Unlike previous years, if you are not already registered, you’re unfortunately out of luck. As seen in Matthias Hauswirth’s terrific guest blog post from last week (see here), getting set up in Clowdr is complicated. ICER won’t have the resources to bring people on-line and get them through the half hour prep sessions on-the-fly. There will be no “onsite” registration.
However, all the papers should be available in the ACM Digital Library (free for some time), and I think all the videos of the talks will be made available after the fact, so you can still gain a lot from the conference. Let me point out a few of the highlights that I’m excited about. (As of this writing, the papers are not yet appearing in the ACM DL — all the DOI links are failing for me. I’ll include the links here in hopes that everything is fixed soon.)
Our keynoter is Tammy Clegg, whom I got to know when she was a PhD student at Georgia Tech. She’s now at U. Maryland doing amazing work around computation and relevant science learning. I’m so looking forward to hearing what she has to say to the ICER community.
Miranda Parker, Allison Elliott Tew, and I have a paper “Uses, Revisions, and the Future of Validated Assessments in Computing Education: A Case Study of the FCS1 and SCS1.” This is a paper that we planned to write when Miranda first developed the SCS1 (first published in 2016). We created the SCS1 in order to send it out to the world for use in research. We hoped that we could sometime later do in CS what Richard Hake did in Physics, when he used the FCI to make some strong statements about teaching practices with a pool of 6,000 students (see paper here). Hake’s paper had a huge impact, as it started making the case to shift from lecture to active learning. Could we use the collected use of the SCS1 to make some strong arguments for improving CS learning? We decided that we couldn’t. The FCI was used in pretty comparable situations, and it’s tightly focused on force. CS1 is far too broad, and FCS1 and SCS1 are being used in so many different places — not all of which it’s been validated for. Our retrospective paper is kind of a systemic literature review, but it’s done from the perspective of tracing these two instruments and how they’ve been used by the research community.
One of the papers that I got a sneak peek at was “When Wrong is Right: The Instructional Power of Multiple Conceptions” by Lauren Margulieux, Paul Denny, Katie Cunningham, Mike Deutsch, and Ben Shapiro. The paper is exploring the tensions between direct instruction and more student-directed approaches (like constructionism and inquiry learning) (see a piece I did in 2015 about these tensions). The basic argument of this new paper is that just telling students the right answer is not enough to develop rich understanding. We have to figure out how to help students to be able to hold and compare multiple conceptions (not all of which is canonical or held by experts), so that they can compare and contrast, and use the right one at the right time.
I’m chair for a session on interest. While I haven’t seen the papers yet, I got to watch the presentations (which are already loaded in Clowdr). “Children’s Implicit and Explicit Stereotypes on the Gender, Social Skills, and Interests of a Computer Scientist” by de Wit, Hermans, and Aivaloglou is a report on a really interesting experiment. They look at how kids associate gender with activities (e.g., are boys more connected to video games than girls?). The innovative part is that they asked the questions and timed the answers. A quick answer likely connects to implicit beliefs. If they take a long time to answer, maybe they told you what they thought you wanted to hear? The second paper “All the Pieces Matter: The Relationship of Momentary Self-efficacy and Affective Experiences with CS1 Achievement and Interest in Computing” by Lishinski and Rosenberg asks about what leads to students succeeding and wanting to continue in computing. They look at students affective state coming into CS1 (e..g, how much do they like computing? How much do they think that they can succeed in computing?), and relate that to students’ experiences and affective state after the class. They make some interesting claims about gender — that gender gaps are really self-efficacy gaps.
One of the more unusual sessions is a pair of papers from IT University of Copenhagen that make up a whole session. ICER doesn’t often give over a whole session to a single research group on multiple papers. One is “Computing Educational Activities Involving People Rather Than Things Appeal More to Women (Recruitment Perspective)” and the other is “Computing Educational Activities Involving People Rather Than Things Appeal More to Women (CS1 Appeal Perspective).” The pitch is that framing CS1 as being about people rather than things leads to better recruitment (first paper) and more success in CS1 (second paper) in terms of gender diversity. It’s empirical support for a hypothesis that we’ve heard before, and the authors frame the direction succinctly: “CS is about people not things.” Is that succinct enough to get CS faculty to adopt this and teach CS differently?
The Bigger Part of Computing Education is outside of Engineering Education
My Blog@CACM post this month is about the differences I’ve seen between computing education and engineering education (see link here). Engineering education has a goal of producing professional engineers. I describe in the post how ASEE is about the profession of engineering, and developing an engineering identity is a critical goal of engineering education. Computing education is about producing software engineers, but that’s only part of what computing education is about. SIGCSE is about learning and teaching of computing, and as computing educators, we teach students with diverse identities. They overlap, but the part of computing education that is outside the intersection with engineering education is much bigger than the part inside.
Computing education for me is about helping people to understand computing (see the Call for Papers for the International Computing Education Research conference) — not just CS education at the undergraduate level. Preparing future software engineers is certainly part of computing education, but sometimes computing educators only see engineering education goals. Computing education has a bigger scope and range than engineering education. Here are three areas where we need to focus on the bigger part outside engineering.
1. K-12 is for everyone. Computing education in elementary and secondary school should be about more than producing software professionals. There are certainly CS teachers who disagree with me. An example is Scott Portnoff’s critique of CS curricula that does not adequately prepare students for the AP CS A exam and the CS major. I agree that we should offer CS courses at secondary school that give students adequate preparation for post-secondary CS education, if students want to go on to a CS major and become a computing professional. But K-12 has to serve everyone, and the most important goals for K-12 CS education are goals for what everyone should learn about computing. We want students:
- To see themselves as capable of doing computer science (the goal of self-efficacy),
- To see the power of the computer in transforming representations, and
- To start on the computer science learning trajectories and discover if they want to learn more.
I am personally much more interested in K-12 teachers using computing to teach everything else better. Computational science and mathematics are powerful for helping scientists and mathematicians gain insight. We should use computing in the same way to advance student learning in STEM, social studies, and other disciplines — without turning those other classes into CS classes. This is the difference that Shuchi Grover is talking about with her two kinds of CT: learning about CS vs using computing to learn other things.
2. Courses for non-CS Majors. I’m co-chairing a task force on computing education for the University of Michigan’s College of Literature, Sciences, & Arts (LSA) (see a blog post on this effort and our website with our NEW preliminary report). I’m learning about the ways that LSA faculty use computing and how they want their students to learn about and use computing. Their purposes are so different from what we teach in classes about computer science or data science. Sure, computational scientists analyze data like data scientists, but they also create models that turn their theories into simulations (which can then generate data). Computational artists use computing to tell engaging stories in new ways. Computational journalists investigate and discover truth with computing. LSA faculty care a great deal about their students critiquing how our computing systems and infrastructure may be unjust and inequitable. (Interesting note: The word “justice” does not appear in the new Computing Curriculum 2020, and the word “equity” appears only once.)
There are computer scientists who tell me that there is only one computer science for all students. Their argument is that better engineering practices help everyone — if those computational scientists, journalists, and artists just programmed like software engineers, the world would be a better place. Their code would be more robust, more secure, and more extensible. That is likely true, but that perspective is misunderstanding the role of code in doing science and making art. You don’t critique the poet for not writing like a journalist or a novelist. These are different activities with different goals.
We should teach non-CS majors with courses that serve their needs, speak to their identities, and support their values. We should not require all artists and scientists to think, act, and program like engineers just to take computing classes.
A CS educator in the Bay area once tried to convince me that the most important purpose for courses for non-CS majors was to identify the potential for being great programmers. He claimed that there are programmers who are two magnitudes better than their peers, and identifying them is the most important thing we can do to support and advance the software companies on which our world economy depends. He argued that we should teach non-CS majors in order to identify and promote future engineers, not for their own purposes. I see his argument, but I do not agree that scientists, journalists, and artists are less important than engineers. As I consider this pandemic, I think about the role that computing has played in medicine, logistics, and media. Of course, we have relied heavily on software engineering, but I don’t believe that it’s more important than all the other roles that computing played.
3. Supporting diverse identities. There is a disconnect between efforts to broaden participation in computing and framing CS classes as engineering education. As I mentioned in my Blog@CACM post, I taught my first EER course this last semester and read a lot of EER papers. A big focus in engineering education is developing an engineering identity, i.e., helping students to see themselves as members of the engineering community of practice and as future professional engineers.
One of my favorite papers that we read this semester was “Feminist Theory in Three Engineering Education Journals: 1995–2008” by Beddoes and Borrego. They define different branches of feminism. “Liberal feminism” is the goal for women to be treated the same as men, to get access to the same jobs at the same pay. “Standpoint feminism” points out that “liberal feminism” is too much about fitting women into the jobs and cultures of men, as opposed to asking how things would be different if created from a feminist standpoint.
The professional identity of software engineering is male and White. That’s true from the demographics of who is in the Tech industry, but it’s also true from a historical perspective on the systemic bias in computing. Computing has become dominated by men, with many studies and books describing how women were forced out (see for example The Computer Boys Take Over and Programmed Inequality). Our tools privilege one part of the world. Every one of our mainstream programming languages is built on English keywords. That’s a barrier for 85% of the people on Earth. (Related point: I recommend Manuel Pérez Quiñones’ TED talk “Why I want My Voice Assistant to Speak Spainglish” in which he suggests that the homogenous background of American software engineers leads to few bilingual user interfaces — surprising when 60% of the human race is.)
There’s the disconnect. We want students in computing with diverse perspectives and identities. But engineering education is about developing an identity as a future professional engineer. Professional software engineering is male and White. How do we prepare diverse students to be future software engineers when that professional identity conflicts with their identities? We should teach computing, even for CS majors, in ways that go beyond the engineering education goal of developing a professional engineering identity.
We might argue that we want everyone to have the opportunity to participate in CS, but that’s taking the “liberal” perspective. Broadening participation should not be about fitting everyone into the same identity. It’s not enough to say that everyone has the chance to learn the programming languages that are based in English, that are grounded in Western epistemologies, and where the contributions of women have been marginalized. We need to find ways to accept and support the unique identities of diverse people.
One way to support a “standpoint” perspective on computing education might be to support activity over identity in our CS curriculum. At Georgia Tech, the undergraduate computer science degree is based on Threads (see website). There are threads for Intelligence, People, Media, Devices, and Theory — eight of them in all. A BS in CS at Georgia Tech is any two threads, so there are 28 paths to a degree. This allows students to define their professional identity in terms of what they are going to DO with computing. “I’m studying People and Devices” is something a student might say who wants to create consumer computational devices like Echo or Roomba. The Threads curriculum allows students to make choices about professional identity, in terms of how they want to contribute to society.
Of course, some of our students want to become software engineers at a FAANG company. That’s great, and we should support them and prepare them for those roles. But we should not require those identities. Computing education is about more than producing software engineers who have the traditional engineering identity.
The Bigger Part of Computing Education. I claimed at the start of this post that “computing education that is outside the intersection with engineering education is much bigger than the part inside.” All the studies I have seen say that’s true. While CS undergraduate enrollment has been exploding, the number of end-user programmers is likely a magnitude larger than the number of professional software developers. K-12 is about 50 million students in the United States, and computing education is available to most of them. The number of computing education students who are NOT seeking an engineering identity or profession is much larger than those who are. That’s the more-than-engineering challenge for computing education.
My thanks to Leo Porter, Cynthia Lee, Adrienne Decker, Briana Morrison, Ben Shapiro, Bahare Naimipour, Tamara Nelson-Fromm, and Amber Solomon who gave me comments on earlier drafts of this post.
Become a Better CS Teacher by Seeing Differently
My Blog@CACM post this month is How I evaluate College Computer Science Teaching. I get a lot of opportunities to read teaching statements and other parts of an academic’s teaching record. I tend to devalue quantitative student evaluations of teaching — they’re biased, and students don’t know what serves them best. What I most value are reports of the methods teachers use when they teach. Teachers who seek out and use the best available methods are mostly likely the best teachers. That is what I look for when I have to review College CS teaching records.
On Twitter, people are most concerned with my comments about office hours. Computer science homework assignments should not be written expecting or requiring everyone in the class to come to office hours in order to complete the assignment. That’s an instructional design problem. If there are questions that are coming up often in office hours, then the teacher should fix the assignment, or add to lecture, or make announcements with the clarification. Guided instruction beats discovery learning, and inquiry learning is improved with instruction. There is no advantage to having everyone in the class discover that they need a certain piece of information or question answered.
My personal experience likely biases me here. I went to Wayne State University in Detroit for undergraduate, and I lived in a northern suburb, five miles up from Eight Mile Road. I drove 30-45 minutes a day each way. (I took the bus sometimes, if the additional time cost was balanced out by the advantage of reading time.) I worked part-time, and usually had two part-time jobs. I don’t remember ever going to office hours. I had no time for office hours. I often did my programming assignments on nights and weekends, when there were no office hours scheduled. If an assignment would have required me to go to office hours, I likely would have failed the assignment. That was a long time ago (early 1980’s) — I was first generation, but not underprivileged. Today, as Manuel pointed out (quoted in this earlier blog post), time constraints (from family and work) are a significant factor for some of our students.
Teachers who require attendance at office hours are not seeing the other demands on their students’ lives. Joe Feldman argues that we ought to be teaching for the non-traditional student, the ones who have family and work demands. If we want diverse students in our classes, we have to learn to teach for the students whose experiences we don’t know and whose time costs we don’t see.
CS teachers get better at what we see
I’m teaching an Engineering Education Research class this semester on “Theoretical and Conceptual Frameworks for Engineering Education Research.” We just read the fabulous chapter in How People Learn on How Experts differ from Novices. One of the themes is on how experts don’t necessarily make good teachers and about the specialized knowledge of teachers (like pedagogical content knowledge). I started searching for papers that did particularly insightful analyses of CS teacher knowledge, and revisited the terrific work of Neil Brown and Amjad Altadmri on “Novice Java Programming Mistakes: Large-Scale Data vs. Educator Beliefs” (see paper here).
Neil and Amjad analyze the massive Blackbox database of keystroke-level data from thousands of students learning Java. They identify the most common mistakes that students make in Java. My favorite analyses in the paper are where they rank these common mistakes by time to fix. An error with curly brackets is very common, but is also very easy to fix. Errors that can take much longer (or might stymie a student completely) include errors with logical operators (ANDs and ORs), void vs non-void return values, and typing issues (e.g., using == on strings vs .equals).
The more controversial part of their analysis is when they ask CS teachers what students get wrong. Teachers’ predictions of the most common errors are not accurate. They’re not accurate when considered in aggregate (e.g., which errors did more teachers vote for) nor when considering the years of experience of a teacher.
Neil and Amjad contrast their findings with work by Phil Sadler and colleagues showing that teacher efficacy is related to their ability to predict student errors (see blog post here).
If one assumes that educator experience must make a difference to educator efficacy, then this would imply that ranking student mistakes is, therefore, unrelated to educator efficacy. However, work from Sadler et al. 2013 in physics found that “a teacher’s ability to identify students’ most common wrong answer on multiple-choice items . . . is an additional measure of science teacher competence.” Although picking answers to a multiple-choice question is not exactly the same as programming mistakes, there is a conflict here—either the Sadler et al. result does not transfer and ranking common student mistakes is not a measure of programming teacher competence, or experience has no effect on teacher competence. The first option seems more likely. (Emphasis added.)
I don’t see a conflict in that sentence. I believe both options are true, with some additional detail. Ranking common student compiler mistakes is not a measure of programming teacher competence. And experience has no effect on teacher competence on things they don’t see or practice.
Expertise is developed from deliberate practice. We get better at the things we work at. CS teachers certainly get better (become more competent) at teaching. Why would that have anything to do with knowing what compiler errors that Java students are getting? Teachers rarely see what compiler errors their students are getting, especially in higher-education with our enormous classes.
When I taught Media Computation, I thought I became pretty good at knowing what errors students got in Python. I worked side-by-side students many times over many years as they worked on their Python programs. But that’s still a biased sample. I had 200-300 students a semester. I might have worked with maybe 10% of those students. I did not have any visibility on what most students were getting wrong in Python. I probably would have failed a similar test on predicting the most common errors in Python based on my personal experience. I’m sure I’d do much better when I rely on studies of students programming in Python (like the study of common errors when students write methods in Python) — research studies let me see differently.
Here at the University of Michigan, I mostly teach a user interface software class on Web front-end programming in JavaScript. I am quite confident that I do NOT know what JavaScript errors my students get. I have 260-360 students a semester. Few come to office hours with JavaScript errors. I rarely see anybody’s code.
I do see exams and quizzes. I know that my students struggle with understanding the Observer Design pattern and MVC. I know that they often misunderstand the Universal Design Principles. I know that CSS and dealing with Java asynchronous processing is hard because that’s where I most often get regrade requests. There I’ll find that there is some unexpected way to get a given effect, and I often have to give points back because their approach works too. I get better at teaching these things every semester.
CS teachers can be expected to become more competent at what they see and focus on. Student compiler errors are rarely what they see. They may see more conceptual or design issues, so that’s where we would expect to see increased teacher competence. To developer teacher competence beyond what we see, we have to rely on research studies that go beyond personal experience.
CS teachers need to get better at teaching those we don’t see
The same principle applies to why we don’t improve the diversity of our CS classes. CS teachers don’t see the students who aren’t there. How do you figure out how to teacher to recruit and retain women and students from Black, Latino/Latina, and indigenous groups if they’re not in your classes? We need to rely on research studies, using others’ eyes and others’ experiences.
Our CS classes are huge. It’s hard to see that we’re keeping students out and that we’re sending a message that students “don’t belong,” when all we see are huge numbers. And when we have these huge classes, we want the majority of students to succeed. We teach to the average, with maybe individual teacher preference for the better students. We rarely teach explicitly to empower and advantage the marginalized students. They are invisible in the sea of (mostly male, mostly white or Asian) faces.
I have had the opportunity over the last few months to look at several CS departments’ diversity data. What’s most discouraging is that the problem is rarely recruitment. The problem is retention. There were more diverse students in the first classes or in the enrolled population — but they withdrew, failed, or dropped out. They were barely visible to the CS teachers, in the sea of huge classes, and they become completely invisible. We didn’t teach in a way that kept these students in our classes.
Our challenge is to teach for those who we don’t easily see. We have to become more competent at teaching to recruit those who aren’t there and retain those students who are lost in our large numbers. We easily become more competent at teaching for the students we see. We need to become more competent at teaching for diversity. We do that by relying on research and better teaching methods, like those I talk about in my Blog@CACM post.
National Academies Report on authenticity to promote computing interests and competencies
The National Academies has now released the report that I’ve been part of developing for the last 18 months or so: “Cultivating Interest and Competencies in Computing: Authentic Experiences and Design Factors.” The report is available here, and you can read it online for free here.
The starting question for the report is, “What’s the role of authentic experiences in developing students’ interests and abilities in computing?” The starting place is a simple observation — lots of current software engineers did things like take apart their toasters as kids, or participate in open-source programming projects as novices. I hear that it’s pretty common in technical interviews to ask students about their GitHub repositories, assuming that that’s indicative of their potential abilities as engineers.
There’s a survivor bias in the observation about toasters and open-source projects. You’re only seeing the people who made it to the software engineering jobs. You’re not seeing the people who were turned off by those activities. You’re not seeing the people who couldn’t even get into open-source projects. Is there a causal relationship? If a student engages in “authentic experiences,” does it lead to greater interest and skill development?
You can skip all the way to Chapter 8 for the findings: We don’t know. There are not enough careful studies exploring the question to establish a causal relationship. But that’s not the most important part of the report.
The key questions of the report really are: “What is an authentic learning experience? What prevents students from getting them?” We came up with two definitions:
- There’s professional authenticity which is what the starting question assumes — the activity has something to do with professional practice in the field.
- There’s personal authenticity which is where the activity is meaningful and interesting to the student.
These don’t have to be in opposition, but they often are. The Tech industry and open-source development is overwhelmingly male and white or Asian. Learning activities that are culturally relevant may be interesting and meaningful to students, but may not obviously connect to professional practice. Activities that are grounded in current practice may not be interesting or meaningful to students, especially if the students see themselves as outsiders and not belonging to the culture of software development (open source or industry). Formal educational systems place a premium on professional, vocational practice, and informal education systems need personal authenticity to keep drawing students in.
The report does a good job covering the research — what we know (and what we don’t), how the issues vary in informal and formal education, and what we can recommend about designing for authenticity (both kinds, without opposition) in learning experiences.
If you ever get the chance participate in a National Academies consensus report, I highly recommend the experience. You’re producing something for the community, so the amount of review and rewriting is significant — more than in any other kind of writing I’ve ever done. It’s worth it. You learn so much! It’s the National Academies, and they gather pretty amazing committees. If you ever get the chance to grab a coffee or beer with any of the participants on the committee, external or staff, take that chance! (I’m not sure I’d recommend chairing or directing one of these committees — the amount of work that Barbara and Amy did was astounding.) Every single one of these folks have amazing insights and experiences. I’m grateful for the opportunity to hang out with them (even when it went all on-line), write with them, and learn from them.

Broadening Participation in Computing is Different in Every State: Michigan as an Example
In December, Rick Adrion, Sarah T. Dunton, Barbara Ericson, Renee Fall, Carol Fletcher, and I published an essay in Communications of the ACM, “U.S. States Must Broaden Participation While Expanding Access to Computer Science Education.” (See link here, and pre-print available at the bottom of this post.). Rick, Renee, Barb, and I were the founders of the ECEP Alliance which helps states and US territories with their computing education policy and practices. Carol is now the PI on ECEP (which feels so great to say — ECEP continues past the founders, with excellent leadership) — the whole leadership team is here. Sarah likely knows more about state-level computing education policy than anyone else in the US. She has worked with individual teams in individual states for years. Our argument is that broadening participation and expanding access are not the same thing. Simply making CS classes available doesn’t get students into those classes. We tell the story of two states (Nevada and Rhode Island) and how CS Ed is growing there.
Barbara and I now live in Michigan. The CSTA, Code.org, and ECEP report 2020 State of Computer Science Education: Illuminating Disparities (see link here) has a sub-report for every US state. Michigan is on page 56. The press release for the 2020 report says that 47% of US high schools now offer CS. Michigan is at 37%. Michigan is the only state (as far as I can tell) that used to have CS teacher certification and pre-service CS but got rid of it (story here).
Also in December, Michigan Department of Education (MDE) released the first “State of Computer Science in Michigan Report” (see link here). The data collection and writing on the report was led by Aman Yadav and Sarah Gretter of Michigan State with Cheryl Wilson of MDE. A quote from page 11: “The trend of declining course offerings continues at the high school level where even fewer high schools offer CS courses. Code.org course offering data suggests that only 23.7% of rural high schools, 28% of town high schools, 29.1% of sub-urban high schools, and 21.7% of city high schools offer CS.” (The numbers on the website are lower than these — Aman and Cheryl kindly sent me an early peek at a revision that they’re posting soon.)
MDE’s numbers are a lot lower than the 37% in the Code.org/CSTA/ECEP report. What’s going on here? My best guess is that CS is rare enough in Michigan that not everybody who fills out a survey knows what the national CS education movement means by “computer science.” We had this a lot in the early days of “Georgia Computes,” too. A principal would say that they teach CS, when they might mean Microsoft Office or Web design (with no HTML, CSS, or JavaScript).
In any case, Michigan is clearly below national averages on providing CS education to its citizens and creating sustainable CS education policy. How do we help Michigan progress in providing computing education to its citizens?
I don’t know. Aman, Barb, and I have had conversations about the potential for growing CS Ed in Michigan. We don’t have the same leverage points in Michigan that we have had in other ECEP states. Michigan is a local control state. Individual local education agencies (LEA’s — sometimes a school district, sometimes a county-wide collection of districts) can make up their own rules on important issues like CS teacher certification. In Georgia and South Carolina, the state government has a lot of control in education, so there was a point of leverage. California is also a local control state, but the California University systems are important to all high schools, so that’s a point of influence. Massachusetts is again a local control state, but the Tech industry is very important to the Boston area, and that’s important to the state. Tech isn’t important in the same way in Michigan. If you read the MDE report, there’s a lot of ambivalence about CS in the state. Administrators aren’t that excited about teaching CS. They don’t see CS education as important for their students. Michigan is a big state, where agriculture and tourism are two of the most significant industries. Manufacturing is a big deal, but manufacturing workers don’t necessarily need to know much about computing. CS isn’t an obvious benefit to much of Michigan.
Aman’s strategy is to grow CS education in the state slowly, to develop pockets of value for CS and success in teaching CS. We have to plant seeds and grow to a critical mass, which seems like the right approach to me. He has projects where he is helping develop teachers and relevant curriculum for CS education in specific counties. He works closely with the MDE. Sarah is involved with Apple’s Developer Academy to open in Detroit (see story here). Michigan does have a powerful and large teacher’s group supporting educational technology, MACUL (Michigan Association for Computer Users in Learning, see website), which could be a significant player in growing CS education in the state.
The important point here is that, in the United States, growing CS education is a state-by-state challenge. Each state has its own story and issues.
Pre-print of CACM BPC article
Promote diversity by teaching to many goals for computing
My Blog@CACM post for this month is about the working definitions of computing that we are developing in a task force at the University of Michigan see post here). We are charged with identifying the computing education needs for undergraduates in the College of Literature, Sciences, and the Arts (LS&A). My post describes three different goals for computing education, based on what LS&A faculty do with computing and what they want their students to know.
- Computing for Discovery
- Computing for Expression
- Critical Computing
In my post, I described how these are different, and about the challenges of meeting all of these educational needs. The biggest challenge I wonder about is the organizational one. Whose job is it to teach to each of these goals?
In this post, I want to argue from a different direction. All of these have a CS component. These aren’t typically priorities in many CS departments. To have more diversity in computer science, we ought to make them a priority.
There’s CS in All of These
Each of the three LS&A themes represent a significant CS research thrust. We distilled them from discussions with faculty in Literature, Sciences, & the Arts, but students could be interested in these themes and seek a computer science degree and career. I’d expect that these themes are more common among students who enter computing from liberal arts and sciences than from engineering.
Computer scientists often create infrastructure and theory for “Computing for Discovery,” from NeurIPS to ACM SIGSIM. At Georgia Tech, there is a School for Computational Science and Engineering. One of my colleagues in that school was Richard Fujimoto, who studied how to run discrete event simulations in parallel and distributed systems. He does his research so that others (scientists or engineers) could do theirs.
Computer scientists invent and create tools to make “Computing for Expression” possible, presented in places like ACM SIGGRAPH and CHI. Alanson Sample joined U-M CSE the same time I did. He was formerly at Disney Research at Pittsburgh, where some of his team worked on the new Pandora exhibits at Disney World. The animatronic Na’vi were difficult for the animators to control, since the robot representation of the aliens were not meant to be human-like. Alanson’s colleagues created new kinds of design tools to support translating facial animations into robotic actuation for the Na’vi. I love that as an example of computer science enabling a new kind of expression.
Technology Review recently published an accessible summary of the paper that led to Timnit Gebru’s being fired from Google (see link here). I knew about Timnit’s work as a scholar in “Critical Computing.” The TR piece did a terrific job explaining the deep CS ideas in their paper — like the potential fallacies of the language models used by Google and the enormous energy costs of running them. Computer science plays an important part in making thoughtful critiques of existing computing systems and infrastructures.
Supporting Diverse Goals for Diverse Students
Imagine that you are a student who has always dreamed of working at Pixar and building tools for animators. Or you are a student who is concerned about creating sustainable IT infrastructure for your community. You decide to pursue a computer science degree, and now you’re in classes about AVL trees or learning the issues between cache coherence and memory consistency. You might very reasonably drop out, to pursue a degree that move clearly helps you better achieves your goals. The problem is that that those are computer science issues. It’s perfectly reasonable to pursue computing education for those goals, but those might not be the goals that most CS Departments at Universities support.
This does happen exactly as I described. Colleen Lewis and her colleagues showed us how it most often happens with candidates who are from groups under-represented in computer science (see blog about the paper here). These students come to computer science with their goals, and if they don’t see how to achieve their goals with the classes they’re given, they lose interest and drop out. Colleen and her students showed that having goals about community values were were more common among students who were female, Black, or Hispanic than students who were male, white, or Asian.
The draft of the 2020 ACM/IEEE Computing Curriculum report is here. It’s a big document, so I might have missed it, but I don’t see these goals represented in the computer science outcomes. Some of these themes are in information systems or information technology. Some of the media fundamentals are in computer engineering. The core of computer science in the 2020 report is focused on “algorithms and complexity, programming languages, software development fundamentals, and software engineering” (quoting page 28). There is very little in the document about justice, equity, and critical consideration of our computing systems and infrastructure.
A student can certainly start from the core of CS and focus on any of these sets of goals — but do students know that? How do we communicate that to them? This was a real problem when we created the Threads program at Georgia Tech where students identify two “threads” of computing which they will combine to create their BS in CS degree program. A student who chooses Media and Theory may be interested in video compression algorithms, and a student who chooses People and Intelligence might be interested in creating explainable AI, but both of those students will be in the same data structures and discrete math classes. We (mostly Charles Isbell and Bill Leahy) made sure that the foundational classes created the narratives that explained how the foundational concepts connected to these Threads. We wanted students to see how their goals were met by the core of CS.
This might be easier in colleges focused on liberal arts and sciences with smaller classes. At my University, I taught the introduction to computing course to 760 students. We regularly have first year CS courses with over 1000 students. It’s very hard to cater to individual student goals at that scale. What we did at Georgia Tech and what we’re doing in our task force at the University of Michigan is to identify common goals and themes, and provide support and narrative for those. We will not reach all students’ goals. We aim to support more student goals than just software development in large Tech firms.
We do our students a disservice if we do not help them see how they can pursue their goals within our undergraduate programs. A computer science degree from a major University is a big deal. It’s worth a lot in the economic marketplace. Is it fair to deny the degree to students who are engaged and curious about computer science because our CS undergraduate programs focus on one set of goals and ignore the others? Computer science is broader than just what the FAANG companies hire. CS undergraduate degree programs should not just be a Silicon Valley jobs program. Universities should support diversity in CS thoughts and goals if we want to have students from diverse backgrounds in computing.
Proposal #3 to Change CS Education to Reduce Inequity: Call a truce on academic misconduct cases for programming assignments
I participated in a Black Lives Matter protest in Ann Arbor a few weeks ago, where I first heard the slogan “Defund the Police.” I was immediately uncomfortable. The current model for police in the US may be broken, but the function of the police is important. But the more I learned, the more I became more comfortable with the idea. As this NYTimes article suggests (see link here), the larger notion gaining support in the US is that we need a reinvestment. We want to spend less on catching criminals, and more on supporting community health and welfare. That’s when I realized what I wanted for my third and final proposal to change CS education to reduce inequity.
This is my four and last post in a series* about how we have to change how we teach CS education to reduce inequity. The series has several inspirations, but the concrete one that I want to reference back to each week is the statement from the University of Maryland’s CS department about improving diversity, equity, and inclusion within their department:
Creating a task force within the Education Committee for a full review of the computer science curriculum to ensure that classes are structured such that students starting out with less computing background can succeed, as well as reorienting the department teaching culture towards a growth mindset
Students don’t learn best by discovery
Paul Kirschner, John Sweller, and Richard Clark have been writing a series of controversial and influential papers in educational psychology. The most cited (in Educational Psychologist) lays out the whole premise in its title “Why minimal guidance during instruction does not work: An analysis of the failure of constructivist, discover, problem-based, experiential, and inquiry-based teaching” (see link here). Another, in American Educator, is a more accessible version “Putting students on the path to learning: The case for fully guided instruction” (see link here). A quick summary of the argument is that learning is hard, and it’s particularly hard to learn if you are trying to “figure things out” or “problem-solve” at the same time. In fact, it’s so hard that, unless you tell students exactly what you want them to learn, the majority of your students probably won’t learn it.
Computer scientists are big believers in discovery learning. I’ve had a senior faculty member in my department tell me that, if they gave students feedback from the unit tests (vs. a binary passed/failed) used in autograding, “we would be stealing from students the opportunity to figure it out for themselves.” I have been interviewing teaching assistants for the Fall. They tell me that if I made my class harder, so students have to struggle more to figure out the programming assignments, they would learn more and retain it longer. I know of little evidence for these beliefs, and none in CS education. Telling students leads to more students learning and learning more efficiently than making them figure it out. Efficiency in learning does matter, especially when we are talking about students who may have competing interests for their time (like a job) and during the stress of a pandemic.
Learning requires challenge, but too much cognitive load reduces learning. My guess is that we believe in the power of struggle because it’s how many of us learned computing. We struggled to figure out undocumented systems, to make things work, and to figure out why they worked. We come away with a rationalization that the process of discovery, without a teacher or guidance, is what led to our learning. The problem is that for experts and high-ability/highly-motivated learners, we like to learn that way. We want to figure it out for ourselves. There is a motivational (affective) value for discovery. However, the available evidence suggests that our belief in discovery is a mirage, a cognitive illusion, a trick we play on ourselves. We don’t learn best by discovery.
What’s worse, by forcing more students to learn by discovery, we will likely drive away the less prepared, the less motivated, and the less able students. That’s the point of this series of blog posts. We as CS teachers make decisions that often emphasize how we wanted to be taught and how our top students want to learn. That is inequitable. We need to teach “such that students starting out with less computing background can succeed.”
Programming assignments should be practice, not assessment
Clark, Kirschner, and Sweller describe how we should be teaching to be most effective and efficient:
Teachers providing explicit instructional guidance fully explain the concepts and skills that students are required to learn. Guidance can be provided through a variety of media, such as lectures, modeling, videos, computer-based presentations, and realistic demonstrations. It can also include class discussions and activities—if the teacher ensures that through the discussion or activity, the relevant information is explicitly provided and practiced. In a math class, for example, when teaching students how to solve a new type of problem, the teacher may begin by showing students how to solve the problem and fully explaining the how and why of the mathematics involved. Often, in following problems, step-by-step explanations may gradually be faded or withdrawn until, through practice and feedback, the students can solve the problem themselves. In this way, before trying to solve the problem on their own, students would already have been walked through both the procedure and the concepts behind the procedure.
Programming assignments are the opportunities to practice in this model, not the time to “figure it out for themselves” and not the time to assess learning or performance. In explicit instruction in programming, the teacher tells the student exactly what to do to solve a programming problem. Tell them how to solve the problem, and let them practice the same problem. (Better yet, give students worked examples and practice interleaved, as we do in our ebooks.) Programming is a great place for learning, since it provides feedback on our tests and hypotheses.
Students should be encouraged to engage in programming practice. The way we do that is by giving points towards grades. We should probably give more points for correct solutions, because that creates desirable incentives. But being able to program does not indicate understanding. The recent ITiCSE 2020 paper by Jean Sala and Diana Franklin showed that use of a given code construct was not correlated well with understanding of that code construct (see paper here). It’s also the case that students may understand the concept but can’t make it work in code.
As I was writing this blog post, the ACM SIGCSE-Members email list had a (yet another!) great thread on how to reduce cheating in CS1. The teachers on the list were torn. They want to support student learning, but they don’t want to reward cheaters. Many echoed this same point — that programming assignments have to be an opportunity for learning, not a summative assessment.
We need to separate learning and assessment activities. Most programming should be a learning opportunity, and not a time to assess student learning. I suppose we might have a special programming assignment labelled, “This one is under exam conditions,” and then it’s clear that it should be done alone and for assessment. I don’t encourage trying to make those kinds of distinctions during remote teaching and learning. I completely understand the reason for plagiarism detecting and prosecution on exams and quizzes. Those are assessment activities, not learning activities.
We should evaluate the students’ programs and give them feedback on them. Feedback improves learning. It shouldn’t be about punishing students who struggle with or even fail at the programs — programming should be part of a learning process.
We can assess learning about programming without having students program
One of our biggest myths in computer science is that the only way to test students’ knowledge of programming is by having them program. Allison Elliott Tew showed that her FCS1 correlated highly with the final exam scores of the students from four courses at two universities who were part of her study (see post here, with diagram of this scatterplot). Her test (all multiple choice) was predicted the grade of the semester’s worth of programming assignments, quizzes, and tests.
Over the years, I’ve attended several AP CS presentations from psyshometricians from ETS. Every time, they show us that they don’t need students to program on the AP CS exams. They can completely predict performance on the programming questions from the multiple choice questions. We can measure the knowledge and skill of programming without having students program.
Of course, it’s easier to tell the students to program, as a way of testing their programming knowledge. However, it’s not an effective measurement instrument (understanding and coding ability are not equivalent), it’s inefficient (takes more time than a test), and it creates stress and cognitive load on the students. (I recommend the work by Kinnunen and Simon on how intro programming assignments depress students’ self-efficacy.) We can and should build better assessments. For example, we could use Parsons problems which are more sensitive measures of understanding about programming than writing programs (see blog post). We want students to program, and most of our students want to program. Our focus should be on improving programming as a learning activity, not as a form of assessment.
Now more than ever, encourage collaboration
Here’s the big ask, Stop prosecuting students for academic misconduct if you detect plagiarism on programming assignments. My argument is just like the policing argument — we should be less worried about catching those who will exploit the opportunity to get unearned points, and more worried about discouraging students from collaboration that will help them learn. We already have inequality in our classrooms. During the pandemic, the gap between the most and less prepared students will likely grow. We have to take specific actions to close that gap and always in favor of the less-prepared students.
Notice that I did not say “stop trying to detect plagiarism.” We should use tools like MOSS to look for potential cheating. But let’s use any detection of plagiarism as an opportunity to learn, and maybe, as a cry for help.
Why do students cheat on programming assignments? There’s a body of literature on that question, but let me jump to the critical insight for this moment in time: All those reasons will be worse this year.
- When we ask students to program, we are saying, “I have shown you all that you need to be able to complete this program. I now want you to demonstrate that you can.” Are we sure about that first part? We’re going to be doing everything online. We might miss covering concepts that we might normally teach, maybe in side conversations. How would we know if we got it wrong this next year?
- One of the most powerful enablers for cheating is that students feel anonymous. If students feel that nobody knows them or notices them, then they might as well cheat. Students are going to feel even more anonymous in remote teaching.
- Finally, at both higher education institutions where I’ve taught, the policy term for cheating is “illicit collaboration.” Especially now in a pandemic with remote teaching, we want students to collaborate. The evidence on pair programming and buddy programming is terrific — it helps with learning, motivation, and persistence in CS. But where’s the line between allowed and illicit collaboration when it’s all over Zoom? I’m worried about students not collaborating because they fear that they’ll cross that line. I have talked to students who won’t collaborate because they fear accidentally doing something disallowed. It will be even harder for students to see that line in a pandemic.
Some students cheat because they think that they have to. “If I don’t cheat and everyone else does, I’m at a disadvantage.” That’s only true if student grades are comparative. That’s why Proposal #2 is a critical step for Proposal #3 — stop pre-allocating, curving, or rationing grades. Use grades to reward learning, not “rising above your peers.”
I worry about us encouraging cheating. The pressures that Feldman identifies as exacerbating cheating will be even greater in all-online learning:
For example, we lament our students’ rampant cheating and copying of homework. Yet when we take a no-excuses approach to late work in the name of preparing students for real-world skills and subtract points or even refuse to accept the work, we incentivize students to complete work on time by hook or by crook and disincentivize real learning. Some common grading practices encourage the very behaviors we want to stop.
Feldman, Joe. Grading for Equity (p. xxii). SAGE Publications. Kindle Edition.
If you detect plagiarism, contact the student. Tell them what you found. Ask them what happened. Ask how they’re doing. Are they getting lost in the class? Use this as an opportunity to explain what illicit collaboration is. Use this as an opportunity to figure out how you’re teaching and what’s going on in the lives of your students. This will be most effective for your first-generation students and your students who are in a minority group. They would likely feel alone, isolated, and invisible even in the in-person class. It’s going to be worse in remote teaching. They are less likely to reach out for help in office hours. Let them know that you’re there and that you care.
Last year, I was in charge of “cheat finding” for a large (over 750 students) introductory programming course. In the end, we filed academic misconduct accusations for about 10% of the class (not all of whom were found guilty by the Honor Council). It was a laborious, time-consuming task — gathering evidence, discussing with the instructional team, writing up the cases, etc. We should have spent that time talking to those students. We would have learned more. They would have learned more. It would have been a better experience for everyone.
Let’s change CS teaching from being about policing over plagiarism, to being about student health, welfare, and development.
* This will be last post for awhile. I’m taking a hiatus from blogging. This series on CS teaching to reduce inequity is my “going out with a bang.”
Proposal #2 to Change CS Education to Reduce Inequity: Make the highest grades achievable by all students
What does an “A” mean in your course? The answer likely depends on why you teach. Research on teacher beliefs suggests that grading practices are related to teachers’ reasons for teaching. Joe Feldman points out that our grading relates to who we are as teachers, and it is passionately held:
Conversations about grading weren’t like conversations about classroom management or assessment design, which teachers approached with openness and in deference to research. Instead, teachers talked about grading in a language of morals about the “real world” and beliefs about students; grading seemed to tap directly into the deepest sense of who teachers were in their classroom.
Feldman, Joe. Grading for Equity (pp. xix-xx). SAGE Publications. Kindle Edition.
I’ve used the Teacher Perspectives Inventory (TPI) (see link here) with dozens of CS teachers. The most common teaching perspective I see among CS teachers is “Apprenticeship.” CS faculty see themselves as preparing future software developers. They value demonstrating and modeling good software practices. An “A” for an apprenticeship teacher is likely to indicate that the student produces good code. An “A” is reserved for “excellence” (as one CS teacher told me recently). An “A” indicates that the student has risen above his or peers in producing “high quality products” (as another CS teacher posted on Facebook recently). An “A” means that, in this teacher’s opinion, the student is recommended to go on to a highly-desired software development job, perhaps at a place like Google or Amazon.
A student with less computing background is much less likely to earn an “A” in an Apprenticeship-oriented class. If you bring more experience to the table, you have a head start on producing higher-quality products than other students in the class. Their products are more likely to be marked as “excellent.”
In my opinion, the teacher attitude of “rugged individualism” defined in SIGCSE 2020 paper by Hovey, Lehmann, and Riggers-Piehl “Linking faculty attitudes to pedagogical choices” meshes with the TPI category of “Apprenticeship.” “Rugged individualism” teachers believe that “learning and success are the individual student’s responsibility.” (Hovey et al did not make this claim or compute the correlation — this is my prediction.) They showed that teachers who believe in “rugged individualism” are less likely to use student-centered teaching practices and more likely to lecture. Students with less computing background do better with student-centered teaching practices.
This is my third post in a series about how we have to change how we teach computing to reduce inequity (see last post). The series has several inspirations, but the concrete one that I want to reference back to each week is the statement from the University of Maryland’s CS department:
Creating a task force within the Education Committee for a full review of the computer science curriculum to ensure that classes are structured such that students starting out with less computing background can succeed, as well as reorienting the department teaching culture towards a growth mindset
The style of grading that means to identify “talent” or “excellence” is inherently inequitable. It presumes a fixed mindset. If you believe that there is a random distribution of “talent” or “ability” or “Geek Gene” in the course, and (critically), there’s nothing much that teaching can do to change that, then it makes sense to grade to the curve. There can be only a few “A” slots, more “B” slots, and so on. Empirical evidence suggests the opposite — good teaching can trump a lot of other factors. Belief in a growth mindset leads to better learning outcomes and better performance. If we value teaching, and believe that students can get better at computer science, then over time, we should teach better and students should learn more. If students learn more, they should get a higher grade It’s not a fixed-result game.
Measure learning or progress towards objectives, not code quality
My teacher perspective is that we are in the job of maximizing individual human development. It’s our job to help each student achieve as much as they can within our discipline. We should measure achievement in terms of learning, not product quality. I tend to align with the “nurturing” perspective on the TPI, but that’s not what I’m going to argue for here.
It is not at all the same thing to grade for excellence and to grade for learning. Writing code isn’t the same as learning. We have evidence that writing a given piece of code is not indicative of understanding that piece of code. The recent ITiCSE 2020 paper by Jean Sala and Diana Franklin showed that use of a given code construct was not correlated well with understanding of that code construct (see paper here).
I mentioned in the last post that I’m reading Grading for Equity by Joe Feldman (see his website here). He points out all the other factors that influence grades that have nothing to do with learning. Some of these extra-curricular factors — like the ability to meet deadlines that presume privileged, full-time student status without outside pressures — are less likely for Black, Hispanic, poorer, or first-generation college students. These factors influence the production of high-quality code even more than they influence learning. These pressures are going to be even greater during a time of a pandemic.
We should give grades depending how much is learned in a given course. That’s hard to do without measuring students as they enter the course and as they leave the course, and grading on the delta. There is a movement suggesting that “labor-based grading” leads to more compassionate and equitable grading (see article here). I’m not arguing for that.
State your criteria clearly and be objective in grading
I’m arguing that we aim for a Teaching Perspective most closely aligned with the one called “Transmission.” The goal of a Transmission teacher is for students to learn what is needed for the next course or to meet the course objectives. Assessments of understanding should be as objective as possible. Grades should represent achievement of the learning objectives and nothing else.
There is a lot in any given CS course that is not about preparing students for the next course in the sequence. We cover a lot of material. In some courses, we’re preparing students for the imagined technical interview with Google or Amazon. That’s not fair to require understanding and performance on standards that go beyond the course objectives.
I recommend setting the objectives clearly, announcing them on the first day, and grading to those. It’s okay to aim for the targeted average on each assignment to be low but passing (e.g., a “C”), as long as you’re clear and fair. In my classes, I rely heavily on weekly quizzes because those are more likely to lead to learning (see post here). I give points for writing code, but that’s to encourage the activity, not to make-or-break the students’ grade. Programming is for learning, and the quizzes, midterm, and final exam are assessments.
Go ahead and bore your best students
Students with a lot of computing background get an easy “A” in my courses. That’s fine. I expect that. I explicitly tell my students that I teach to the bottom third of the course. I want to move B and C students up into A’s and B’s. I give out a lot of A’s. In years past, I did a series of blog posts on “Boredom vs Failure” (here’s the first post in the series, and here’s the last one). The question is: which is worse, to bore and give easy A’s to the most privileged and most prepared students, or to fail (or discourage to the point that they drop) the students with less privilege and the least computing background? Think about the students who might fail or drop out in a system that makes sure that the most well prepared students are challenged. Each one of those students who continues on does more to change the status quo than does keeping the more privileged students from getting bored. Helping the students with less computing background succeed makes a much bigger difference for society long-term than does keeping entertained the most privileged students.
One response to this proposal is that I’m degrading the value of past A’s. The A’s don’t mean the same thing anymore. That’s true. I take a historical perspective. Those A’s were earned when the students with less computing background were not being taught with methods that helped them succeed (Proposal #1). Those A’s were earned in unfair competition, where the students with prior computing background were compared to students with less computing background. I’m proposing a more just system where the students with less computing background have a chance at the highest grades, where they’re taught in ways that meet their needs, and where their teachers believe that they can grow and improve. I’m not particularly concerned about preserving the past glories of those who won in an unjust system.
If we pre-allocate, ration, or otherwise curve “down” grades so that the top scores are a scarce resource in a competitive system, we are privileging the most prepared students and disadvantaging the least prepared students. I am proposing differentiated instruction. Teach explicitly for the least-prepared students. You will likely have to give up on pushing your top students to greater excellence — that’s the kind of privilege which we have to be willing to surrender. Aim to help every student achieve their potential, and if you have to make a choice, make choices in favor of the students with less privilege and less computing background.
Proposal #1 to Change CS Education to Reduce Inequity: Teach computer science to advantage the students with less computing background
This is my second post in a series about how we have to change how we teach CS education to reduce inequity. I started this series with this post, making an argument based on race, but might also be made in terms of the pandemic. We have to change how we teach CS this year.
The series has several inspirations, but the concrete one that I want to reference back to each week is the statement from the University of Maryland’s CS department:
Creating a task force within the Education Committee for a full review of the computer science curriculum to ensure that classes are structured such that students starting out with less computing background can succeed, as well as reorienting the department teaching culture towards a growth mindset
We as individual computing teachers make choices that influence whether students with less computing background can succeed. I often see choices being made that encourage the most capable students, but at the cost of the least prepared students. Part of this is because we see ourselves as preparing students for top software engineering jobs. The questions that get asked on technical interviews explicitly drive how many CS departments teach algorithms and theory. We want to encourage “excellence.” But whose excellence do we care about? Is Silicon Valley entrepreneurial perspectives the only ones that matter? The goal of “becoming a great software engineer” does not consider alternative endpoints for computing education (see post here). Not all our students want those kinds of jobs. Many of our students are much more interested in giving back to their community, rather than take the Silicon Valley jobs that our programs aim for (see post here).
Please don’t teach students as if they are you. First, you (as a CS teacher, as someone who reads this blog) are wildly different than our normal student. Second, your memories of how you learned and what worked for you are likely wrong. Humans are terrible at reconstructing how their memory was at a prior time and what led to their learning. That’s why we need research.
In this post, I will identify four of the methods that are differential, that advantage the students with less computing background — there are many more:
- Use Peer Instruction
- Explain connection to community values
- Use Parsons Problems
- Use subgoal labeling
Use Peer Instruction
When I talk to computer science teachers about peer instruction and how powerful it is for learning, the most common response is, “Oh, we already do that.” When I press them, they tell me that they “have class discussions” or “use undergraduate teaching assistants.” Nope, that’s not peer instruction.
Peer instruction (PI) is a technical term meaning a very specific protocol. Digital Promise and UTeach are creating a set of CS teaching micro credentials, and the one that they have on PI defines it well (see link here). PI is where the teacher poses a question for the class for individual responses, students discuss their answers, students respond again, and the teacher reveals the answer and explains the answer. The evidence suggesting that PI really works is overwhelming, and it can be used in any CS class — see http://peerinstruction4cs.com/ for more information on how to do it. I use it regularly in Senior-level undergraduate courses and graduate courses. There are ways to do PI when teaching remotely, as I talked about in this post.
I’m highlighting PI because the evidence suggests that it has a differential impact (see study here). It doesn’t hurt the top students, but it reduces failure rate (measured in multiple CS courses) for students with less background (see paper here). That’s exactly what we’re looking for in this series — how do we improve the odds of success for students who are not in the most privileged groups.
Explain connection to community values
I blogged last year about a paper (see post here) that showed female, Black, Latino/Latina, and first-generation students take CS because they want to help society. These students often do not see a connection between what’s being taught in CS classes and what they want. That’s because we often teach to prepare students for top software engineering jobs — it’s a mismatch between our goals and their goals.
I don’t know if this is an issue in upper-level classes. Maybe students in upper-level classes have already figured out how CS connects to their goals and values. Or maybe we have already filtered out the CS students who care about community values by the upper-level and graduate courses.
CS can certainly be used to advance social goals and community values. Teach that. In every CS class, for everything you teach, explain concretely how this concept or skill could be used to advance social good, cultural relevance, and community values. If you can’t, ask yourself why you’re teaching this concept or skill. If it’s just to promote a Silicon Valley jobs program, consider dropping it. We are all revising our classes this summer for fall. It’s a good time to do this review and update.
Use Parsons Problems
Parsons problems (sometimes referred to as “mixed-up code problems”) are where students are given a programming problem, and given all the lines of code to solve the problem, but the lines are scrambled (I usually say “on refrigerator magnets”). The challenge is to assemble the correct program. My wife, Barbara Ericson, did her dissertation work (see post here) showing that Parsons problems were effective (led to the same learning as writing the programs from scratch or from debugging programs) and efficient (low time cost, low cognitive load). She also invented dynamically adaptive Parsons problems which are even better (for effectiveness and efficiency) than traditional Parsons problems.
Parsons problems work on-line, so they fit into remote teaching easily. I’ve been doing paper-based (and Canvas-based) Parsons for exams and quizzes for several years now (see post here). Parsons problems work great in lower-level classes. There is relatively little research on using them in upper-level and graduate courses — I suspect that they could be useful, if only to break up the all-coding-all-the-time framing of CS classes.
I’m highlighting Parsons problems for two reasons.
- First, they’re efficient. As Manuel noted (as I quoted in my Blog@CACM post), BIPOC students are much more likely to be time-stressed than more privileged students. I’m reading Grading for Equity by Joe Feldman which makes this point in more detail (see website). Our less-privileged students need us to find ways to teach them efficiently. This is going to be a particularly concern during a pandemic when students will have more time constraints, especially if they, or a relative, or someone they live becomes ill.
- Second, they are a more careful and finer-grained assessment tool (see this post). If you ask students with less ability to write a piece of code, you might get students who only get part of the code working, but you get little data from students who only knew how to write part of the code but get none of it working. Parsons problems help the students with less computing background to show what they do know, and to help the teacher figure out what they don’t know how to write yet.
Use subgoal labelling
Subgoal labelling is pretty amazing (see Wikipedia page). Even our first experiment with subgoal labelling for CS worked examples (see post here) has shown improvements in learning (measured immediately after instruction), retention (measured a week later), and transfer (student success on a new task without instruction). Since then, Lauren Margulieux, Briana Morrison, and Adrienne Decker have published a slew of great results.
The one that makes it on this list is their most recent finding (see post here). Subgoal labeling in an introductory computing course, compared to one not using subgoal labeling, led to reduced drop or failure rates. That’s a differential benefit. There was not a statistically significant improvement on learning (measured in terms of exam scores), but it kept the students most at risk of failing or dropping out in the course. That’s teaching to advantage the students with less background in computing. We don’t know if it works for upper-level or graduate classes — my hypothesis is that it would.
Changing Computer Science Education to eliminate structural inequities and in response to a pandemic: Starting a Four Part Series
George Floyd’s tragic death has sparked a movement to learn about race and to eliminate structural inequities and racism. My email is flooded with letters and statements demanding change and recommending actions. These include a letter from Black scholars and other members of the ACM to the leadership of the ACM (see link here), the Black in Computing Open Letter and Call to Action (see link here, and the Hispanics in Computing supportive response link here). The letter about addressing institutional racism in the SIGCHI community from the Realizing that All Can be Equal (R.A.C.E) is powerful and enlightening (see link here).
I’m reading daily about race. I’m not an expert, or even particularly well-informed yet. One of the books I’m reading is Me and White Supremacy by Layla F. Saad (see Amazon link here) where the author warns against:
Using perfectionism to avoid doing the work and fearing using your voice or showing up for antiracism work until you know everything perfectly and can avoid being called out for making mistakes.
This post is the start of a four part series about what we should be changing in computing education towards eliminating structural inequities. We too often build computing education for the most privileged, for the majority demographic groups. It’s past time to support alternative pathways into computing. Even if you’re not driven by concerns about racial injustice, I ask you to take my proposals seriously because of the pandemic. We don’t know how to teach CS remotely at this enormous scale over the next year, and the least-privileged students will be hurt the most by this. We must CS teach differently so that we eliminate the gap between the most and least privileged of our students. Here’s what we need to do.
Learn about Race
Amber Solomon, a PhD student working with Betsy DiSalvo and me, reviewed my first two posts about race in CS Education (at Blog@CACM and here a few weeks ago). Amber has written on intersectionality in CS education, and is writing a dissertation about the role of embodied representations in CS education (see a post here about her most recent paper). She recommended more on learning about race:
- Whiteness as Property by Cheryl Harris (see link here). Harris, Andre Brock, and some race scholars, argue that to understand racism, you should understand whiteness, not Blackness.
- The Matter of Race in Histories of American Technology by Herzig (see link here). She has the clearest explanation of “race and/as technology” that I’ve read. And she also does a great job explaining why we can’t just say that race is a social construct.
Two videos:
- Repurposing Our Pedagogies: Abolitionist Teaching in a Global Pandemic (see YouTube link here).
- Data, AI, Public Health, Policing, the Pandemic, and Un-Making Carceral States (see YouTube link here). it’s about data, but they get into what it means to be racially Black, white, etc.; and Ruha says something super interesting “rather than collecting racial data, think about what it would mean to collect data on racism.”
Think about the words you use, like “Underrepresented Minority”
Tiffani Williams wrote a Blog@CACM post in June that made an important point about the term “underrepresented minority” (see link here). She argues that it’s a racist term and we should strike it from our language.
Reason #1: URM is racist language because it denies groups the right to name themselves.
Reason #2: URM is racist language because it blinds us to the differences in circumstances of members in the group.
Reason #3: URM is racist language because it implies a master-slave relationship between overrepresented majorities and underrepresented minorities.
In Me and White Supremacy, Saad uses BIPOC (Black, Indigenous, and People of Color), but points out that that is mostly a shorthand for “people lacking white privilege.” She argues, as does Williams, that the term BIPOC ignores the differences in experience between people in those groups. I am striving to be careful in my language and be thoughtful when I use terms like “BIPOC” and “underrepresented.”
Change Computing Departments
Amy Ko has made some strong and insightful posts in the last month about the injustice and exclusion in CS education (see Microsoft presentation slides here). She wrote a powerful post about why her undergraduate major in Information Technology at the University of Washington is racist (see link here). Obviously, her point is that it’s not just her program — certainly the vast majority of computing majors are racist in the ways that she describes. There are mechanisms that are better, like the lottery I described recently to reduce the bias in admission to the major. Amy’s points are inspiring this blog post series.
Manuel Pérez-Quiñones has started blogging, with posts on what CS departments should do to dismantle racism (see link here) and about why CS departments should create more student organizations to combat racism (see link here). His first post has a quote that inspires me:
First, it should come as no surprise that many things we assume to be fair, standard, or just plain normal in reality are not. Even our notion of “fair” has been constructed from a point of view that prioritizes fairness for certain groups. Not only is history written by the victors; laws, structures, and other pieces of society are developed by them too. To expect them to be fair or equitable is naive at best.
Chad Jenkins shared with me a video of his keynote from the RSS 2018 Conference where he suggests that CS departments need to change their research focus, too, to incorporate a value for equity and human values.
The Chair of our department’s Diversity, Equity, and Inclusion (DEI) Committee, Wes Weimer, is pushing for all Computer Science departments to be transparent about how they’re doing on their goals to make CS more diverse and equitable, and what their plans are. The Computer Science & Engineering division at the University of Michigan is serving as an example by making its annual DEI report publicly available here. In the comments, please share your department’s DEI report. Let’s follow Wes’s lead and makes this the common, annual practice.
Change how we teach Computing
Manuel’s point isn’t just about departments. We as individual teachers of computer science and computing make choices which we think are “fair, standard” but actually support and enforce structural inequities. We have to change how we teach. CS for All has published a statement on anti-racism and injustice (see link here) where they say:
We pledge to repeatedly speak out against our historical pedagogies and approaches to computer science instruction that are grounded and designed to weed out all but a small prerogative subset of the US population.
Chad Jenkins mailed me the statement from the University of Maryland’s CS department about their recommendations to improve diversity and inclusion. I loved this quote, which will be the theme for this series of posts:
Creating a task force within the Education Committee for a full review of the computer science curriculum to ensure that classes are structured such that students starting out with less computing background can succeed, as well as reorienting the department teaching culture towards a growth mindset
We currently teach computer science in ways that “weed out all but a small prerogative subset of the US population” (CS for All). We need to teach so that “students starting out with less computing background can succeed” (UMdCS). We teach in ways that assume a fixed mindset — we presume that some students have a “Geek Gene” and there’s nothing much that teaching can do to change that. We know the opposite — teaching can trump genetics.
Even if you don’t care about race or believe that we have created structural inequities in CS education, I ask you to change because of the pandemic. Teaching on-line will likely hurt our students with the least preparation (see post here). We have to teach differently this year when students will have fewer resources, and we are literally inventing our classes anew in remote forms. If we don’t teach differently, we will increase the gap between those more or less computing background.
While I am just learning about race, I have been studying for years how to teach computing to people with less computing background. This is what this series of posts is about. In the next three posts, I make concrete recommendations about how we should teach differently to reduce inequity. I hope that you are inspired by the desire to eliminate racial inequities, but if not, I trust that you will recognize the need to teach differently because of the pandemic.
First step: Stop using pseudocode on the AP CS Principles Exam
Here’s an example of a structural inequity that weeds out students with less computing background. The AP CS Principles exam (see website here) is meant to be agnostic about what programming language the students are taught, so the programming problems on the actual exam are given in a pseudocode — either text or block-based (randomly). There is no interpreter generally available for the pseudocode, so students learn one language (maybe Snap! or Scratch or MIT App Inventor) and answer questions in another one.
Advanced Placement (AP) classes are generally supposed to replicate the experience of introductory courses at College. AP CSP is supposed to map to a non-CS majors’ intro to computing course. How many of these teach in language X, but then ask students to take their final exam in language Y which they’ve never used?
Allison Elliott Tew’s dissertation (see link here) is one of the only studies I know where students completed a validated instrument both in a pseudocode and in whatever language they learned (Java, MATLAB, and Python in her study). She found that the students who scored the best on the pseudocode exam had the closest match in scores between the pseudocode exam and the intro language exam — averaging a difference in 2.31 answers out of the 27 questions on the exams (see table below.). But the average difference increases dramatically. For the bottom two quartiles, the difference is 17% (4.8 questions out of 27) and 22% (6.2 questions out of 27). It’s not too difficult for students in the best-performing quartile to transfer their knowledge to the pseudocode, but it’s a significant challenge for the lowest-performing two quartiles. These results suggest predict that giving the AP CSP exam in a pseudocode is a barrier, which is easily handled by the most prepared students and is much more of a barrier for the least prepared students.
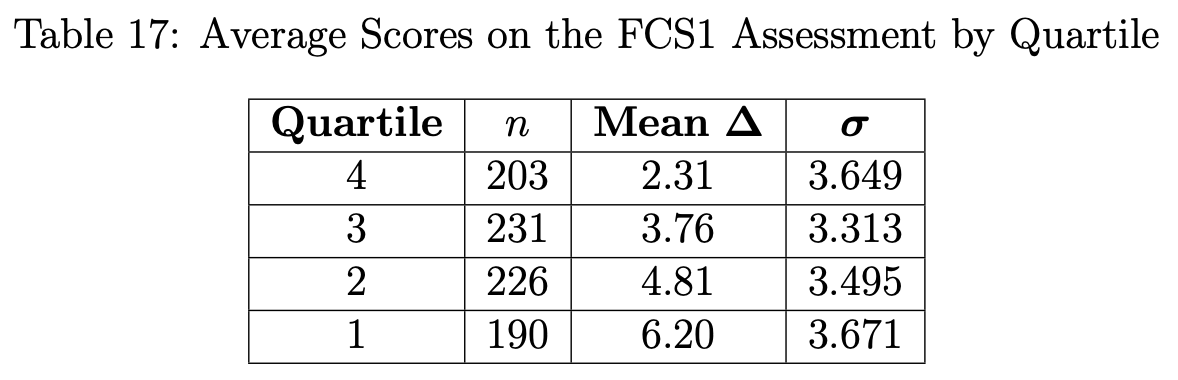
I went to a bunch of meetings around the AP CSP exam when it was first being set up. At a meeting where the pseudocode plans were announced, I raised the issue of Allison’s results. The response from the College Board was that, while it was a concern, it was not likely going to be a significant problem for the average student. That’s true, and I accepted it at the time. But now, we’re aware of the structural inequities that we have erected that “weed out all but a small prerogative subset of the US population” (CS for All). It’s not acceptable that switching to a pseudocode dramatically increases the odds that students in the bottom half fail the AP CSP exam, when they might have passed if they were given the language that they learned.
Further, studies of block-based and text languages in the context of AP CSP support the argument that students overall do better in a block-based language (see this post here as an example). Every text-based problem decreases the odds that female, Black, and Hispanic students will pass the exam (using the race labels the students use to self-identify on the exam). If the same problem was in a block-based language, they would likely do better.
Using pseudocode on the AP CSP exam is like a tax. Everyone has to manage a bit more difficulty by mapping to a new language they’ve never used. But it’s a regressive tax. It’s much more easily handled by the most privileged and most prepared students.
AP CSP is an important program that is making computing education available to students who otherwise might never access a CS course. We should grow this program. But we should scrap the AP CSP exam in its current form. I understand that the College Board and the creators of the AP CSP exam were aiming with the pseudocode, mixed-modality exam to create freedom for schools and teachers to teach with whatever the language and curriculum they wanted. However, we now know that that flexibility comes at a cost, and that cost is greater for students with less computing background, with less preparation, and who are female, Black, or Hispanic. This is structural inequity.
Managing CS major enrollment boom with a lottery: “A lottery, by definition, is fair.”
I am excited to see that the University of California, San Diego is now managing their over-enrollment in the computer science major with a lottery — see the article here.
Instead of enrolling students holistically or based on GPA, the department selects at random — assuming they exceed the 3.3 CSE GPA threshold. With the lottery system, all students are equally considered despite differences in their experience, drive, and ability.
When asked about the implications of the new system — and possible disadvantage to high-performing students — CSE Chair Dean Tullsen explained, “a lottery, by definition, is fair.”
“I think there’s this false assumption that the students who work harder are the ones who are getting the 4.0s, that hard work directly translates to a higher grade. [The lottery system will] admit a lot of hard-working students who weren’t getting in before,” CSE Vice-Chair for Undergraduate Education Christine Alvarado added.
This is a much more fair system than simply allowing in the top GPA students. It probably doesn’t make Tech companies happier, but it’s not clear that it makes them less happy. They will still get lots of potential employees who are above the bar. Those employees will likely be more diverse than the graduates being produced from CS programs today. The students getting the top grades in the early classes are typically those with more opportunity to learn CS, more wealth, and more privilege. A lottery says that anyone who is prepared for the courses can take them.
Importance of considering race in CS education research and discussion
I was talking with one of my colleagues here at Michigan about the fascinating recent journal article from Tim Weston and collaborators based on NCWIT Aspirations award applicants, which I blogged about here. I was telling him about the results — what correlated with women’s persistence in technology and computing, and what didn’t or was negatively correlated.
He said that he was dubious. I asked why. He said, “What about the Black girls?”
His argument that the NCWIT Aspirations awards tends to be white and tends to be in wealthy, privileged school districts. Would those correlations be the same if you looked at Black women, or Latina women?
I went back to the Weston et al. paper. They write:
Although all respondents were female, they were diverse in race and ethnicity. Because we know that there are differentiated experiences for students of color in secondary and post-secondary education in the US, and especially women of color, we wanted to make sure we captured any differences in outcomes in our analysis. To do so, we created a variable called Under-represented Minority in Computing (URMC) status that grouped students by race/ethnicity. URMC indicated persons from groups historically under-represented in computing–African-American, Hispanic, or Native American. White, Asian and students of two or more races were coded as “Majority” in this variable. Unfortunately, further disaggregation by specific race/ethnicity was not possible due to low numbers. Thus, even though the numbers in the respondent pool were not high enough to disaggregate by specific race/ethnicity, we could still identify trends by over-representation and under-representation.
18% of their population was tagged URMC. URMC was included as a variable in their analyses, and their results suggest that being in the URMC group did not influence persistence significantly. If I understand their regressions right, that doesn’t tell us if the correlations were different by race/ethnicity. URMC wasn’t a significant factor in the outcomes, but that is not the same as thinking that those other variables differ by race and ethnicity. Do Black females have a different relationship with video games or with community than white females, for example? Or with Latina students?
While the analysis did not leave race out of the analysis entirely, there was not enough diversity there to answer my colleague’s question. I do agree with the authors that we would expect differentiated experiences. If our analysis does not include race, can we account for the differentiated experiences?
It’s hard to include race in many of our post-secondary CS ed analyses simply because the number of non-white and non-Asian students is so small. We couldn’t say that Media Computation was successful with a diverse student body until University of Illinois Chicago published their results. Georgia Tech has few students from under-served groups in the CS classes we were studying.
There’s a real danger that we’re going to make strong claims about what works and doesn’t work in computer science based only on what works for students in the majority groups. We need to make sure that we include race in our CS education discussions, that we’re taking into account these differentiated experiences. If we don’t, we risk that any improvements or optimizations we make on the basis of these results will only work with the privileged students, or worse yet, may even exacerbate the differentiated experiences.
Why some students do not feel that they belong in CS, and how we can encourage the sense that they do belong
One of my favorite papers at ICER 2019 was by Colleen Lewis and her colleagues, and is available on her website. I’ll quote her first:
Does a match between a students’ values of helping society and their perception of computing matter? Yes! A mismatch between a students’ goals of helping society and their perception of computing predicts a lower sense of belonging. And students from groups who – on average – are more likely to want to help society (women, Black students, Latinx students, and first-generation college students), this may be particularly problematic! (pdf)
- Lewis, C. M., Bruno, P., Raygoza, J., & Wang, J. (2019). Alignment of Goals and Perceptions of Computing Predicts Students’ Sense of Belonging in Computing.Proceedings of the International Computer Science Education Research Workshop. Toronto, Canada.
I want to expand a bit on that paragraph. I often get the question, “Why aren’t more women and URM students going into CS?” We’re seeing female students and students of color leaving/avoiding CS at many stages, e.g., Barb’s deep analysis of AP CS*. Colleen and her collaborators are giving us one answer.
We know that students who have a sense of belonging in computing are more likely to stay in computing. Colleen et al. found that students who found that their values were supported in computing were more likely to feel a sense of belonging. So, if what you want to do with your life matches computing, you’re more likely to stick around in computing. This is the “alignment of goals” and “perceptions of computing” part of the title.
Next step: Students from demographic groups underrepresented in computing were more likely to value community and helping society than other students. These are their goals. Do students see that their goals align with their perception of computing? If so, then you have an increased sense of belonging. Colleen and her colleagues found that If the students who valued community perceived that they could use computing to support communal values, then they were more likely to stick around.
This result is obviously explanatory. It helps us to understand who stays in computing. It also suggests interventions. Want to retain more under-represented students in your CS classes? Help them to see that they can pursue their values in computing. Help them to update their perceptions so that they see the alignment of their goals with computing goals.
But what if you (as the teacher) don’t? This paper suggests future research questions. What if your CS class is entirely de-contextualized and doesn’t say anything about what the students might do with computing? What perceptions do the students bring to the CS class if nobody helps them to see the possibilities in computing? Which student goals align with these perceived goals of computing? We might guess what the answers might be, but it really does call for some explicit research. What are students’ goals and perceptions of computing in most CS classes today?
* Check out Barb’s blog at https://cs4all.home.blog/. As I’m writing this, Barb is finishing up the 2019 AP analysis. The gap between white and Black student pass rates on AP CSP is enormous, far larger than the gap on AP CS A. I’m hoping that she has updates there by the time this post appears.

Recent Comments