Posts tagged ‘subgoal labeling’
Proposal #1 to Change CS Education to Reduce Inequity: Teach computer science to advantage the students with less computing background
This is my second post in a series about how we have to change how we teach CS education to reduce inequity. I started this series with this post, making an argument based on race, but might also be made in terms of the pandemic. We have to change how we teach CS this year.
The series has several inspirations, but the concrete one that I want to reference back to each week is the statement from the University of Maryland’s CS department:
Creating a task force within the Education Committee for a full review of the computer science curriculum to ensure that classes are structured such that students starting out with less computing background can succeed, as well as reorienting the department teaching culture towards a growth mindset
We as individual computing teachers make choices that influence whether students with less computing background can succeed. I often see choices being made that encourage the most capable students, but at the cost of the least prepared students. Part of this is because we see ourselves as preparing students for top software engineering jobs. The questions that get asked on technical interviews explicitly drive how many CS departments teach algorithms and theory. We want to encourage “excellence.” But whose excellence do we care about? Is Silicon Valley entrepreneurial perspectives the only ones that matter? The goal of “becoming a great software engineer” does not consider alternative endpoints for computing education (see post here). Not all our students want those kinds of jobs. Many of our students are much more interested in giving back to their community, rather than take the Silicon Valley jobs that our programs aim for (see post here).
Please don’t teach students as if they are you. First, you (as a CS teacher, as someone who reads this blog) are wildly different than our normal student. Second, your memories of how you learned and what worked for you are likely wrong. Humans are terrible at reconstructing how their memory was at a prior time and what led to their learning. That’s why we need research.
In this post, I will identify four of the methods that are differential, that advantage the students with less computing background — there are many more:
- Use Peer Instruction
- Explain connection to community values
- Use Parsons Problems
- Use subgoal labeling
Use Peer Instruction
When I talk to computer science teachers about peer instruction and how powerful it is for learning, the most common response is, “Oh, we already do that.” When I press them, they tell me that they “have class discussions” or “use undergraduate teaching assistants.” Nope, that’s not peer instruction.
Peer instruction (PI) is a technical term meaning a very specific protocol. Digital Promise and UTeach are creating a set of CS teaching micro credentials, and the one that they have on PI defines it well (see link here). PI is where the teacher poses a question for the class for individual responses, students discuss their answers, students respond again, and the teacher reveals the answer and explains the answer. The evidence suggesting that PI really works is overwhelming, and it can be used in any CS class — see http://peerinstruction4cs.com/ for more information on how to do it. I use it regularly in Senior-level undergraduate courses and graduate courses. There are ways to do PI when teaching remotely, as I talked about in this post.
I’m highlighting PI because the evidence suggests that it has a differential impact (see study here). It doesn’t hurt the top students, but it reduces failure rate (measured in multiple CS courses) for students with less background (see paper here). That’s exactly what we’re looking for in this series — how do we improve the odds of success for students who are not in the most privileged groups.
Explain connection to community values
I blogged last year about a paper (see post here) that showed female, Black, Latino/Latina, and first-generation students take CS because they want to help society. These students often do not see a connection between what’s being taught in CS classes and what they want. That’s because we often teach to prepare students for top software engineering jobs — it’s a mismatch between our goals and their goals.
I don’t know if this is an issue in upper-level classes. Maybe students in upper-level classes have already figured out how CS connects to their goals and values. Or maybe we have already filtered out the CS students who care about community values by the upper-level and graduate courses.
CS can certainly be used to advance social goals and community values. Teach that. In every CS class, for everything you teach, explain concretely how this concept or skill could be used to advance social good, cultural relevance, and community values. If you can’t, ask yourself why you’re teaching this concept or skill. If it’s just to promote a Silicon Valley jobs program, consider dropping it. We are all revising our classes this summer for fall. It’s a good time to do this review and update.
Use Parsons Problems
Parsons problems (sometimes referred to as “mixed-up code problems”) are where students are given a programming problem, and given all the lines of code to solve the problem, but the lines are scrambled (I usually say “on refrigerator magnets”). The challenge is to assemble the correct program. My wife, Barbara Ericson, did her dissertation work (see post here) showing that Parsons problems were effective (led to the same learning as writing the programs from scratch or from debugging programs) and efficient (low time cost, low cognitive load). She also invented dynamically adaptive Parsons problems which are even better (for effectiveness and efficiency) than traditional Parsons problems.
Parsons problems work on-line, so they fit into remote teaching easily. I’ve been doing paper-based (and Canvas-based) Parsons for exams and quizzes for several years now (see post here). Parsons problems work great in lower-level classes. There is relatively little research on using them in upper-level and graduate courses — I suspect that they could be useful, if only to break up the all-coding-all-the-time framing of CS classes.
I’m highlighting Parsons problems for two reasons.
- First, they’re efficient. As Manuel noted (as I quoted in my Blog@CACM post), BIPOC students are much more likely to be time-stressed than more privileged students. I’m reading Grading for Equity by Joe Feldman which makes this point in more detail (see website). Our less-privileged students need us to find ways to teach them efficiently. This is going to be a particularly concern during a pandemic when students will have more time constraints, especially if they, or a relative, or someone they live becomes ill.
- Second, they are a more careful and finer-grained assessment tool (see this post). If you ask students with less ability to write a piece of code, you might get students who only get part of the code working, but you get little data from students who only knew how to write part of the code but get none of it working. Parsons problems help the students with less computing background to show what they do know, and to help the teacher figure out what they don’t know how to write yet.
Use subgoal labelling
Subgoal labelling is pretty amazing (see Wikipedia page). Even our first experiment with subgoal labelling for CS worked examples (see post here) has shown improvements in learning (measured immediately after instruction), retention (measured a week later), and transfer (student success on a new task without instruction). Since then, Lauren Margulieux, Briana Morrison, and Adrienne Decker have published a slew of great results.
The one that makes it on this list is their most recent finding (see post here). Subgoal labeling in an introductory computing course, compared to one not using subgoal labeling, led to reduced drop or failure rates. That’s a differential benefit. There was not a statistically significant improvement on learning (measured in terms of exam scores), but it kept the students most at risk of failing or dropping out in the course. That’s teaching to advantage the students with less background in computing. We don’t know if it works for upper-level or graduate classes — my hypothesis is that it would.
Subgoal labelling influences student success and retention in CS
I have written a lot about subgoal labeling in his blog. Probably the best way to find it all is to see the articles I wrote about Lauren’s graduation (link here) and Briana’s (link here). They have continued their terrific work, and have come out with their most impressive finding yet.
In work with Adrienne Decker, they have shown that subgoal labeling reduces the rate at which students fail or drop out of introductory computer science classes: “Reducing withdrawal and failure rates in introductory programming with subgoal labeled worked examples” (see link here). The abstract is below.
We now have evidence that subgoal labelling lead to better learning, better transfer, work in different languages, work in both text and block-based programming languages, and work in Parsons Problems. Now, we have evidence that their use leads to macro effects, like improved student success and retention. We also see a differential impact — the students most at risk of failing are the ones who gain the most.
This is a huge win.
Abstract
Background: Programming a computer is an increasingly valuable skill, but dropout and failure rates in introductory programming courses are regularly as high as 50%. Like many fields, programming requires students to learn complex problem-solving procedures from instructors who tend to have tacit knowledge about low-level procedures that they have automatized. The subgoal learning framework has been used in programming and other fields to breakdown procedural problem solving into smaller pieces that novices can grasp more easily, but it has only been used in short term interventions. In this study, the subgoal learning framework was implemented throughout a semester-long introductory programming course to explore its longitudinal effects. Of 265 students in multiple sections of the course, half received subgoal-oriented instruction while the other half received typical instruction.
Results: Learning subgoals consistently improved performance on quizzes, which were formative and given within a week of learning a new procedure, but not on exams, which were summative. While exam performance was not statistically better, the subgoal group had lower variance in exam scores and fewer students dropped or failed the course than in the control group. To better understand the learning process, we examined students’ responses to open-ended questions that asked them to explain the problem-solving process. Furthermore, we explored characteristics of learners to determine how subgoal learning affected students at risk of dropout or failure.
Conclusions: Students in an introductory programming course performed better on initial assessments when they received instructions that used our intervention, subgoal labels. Though the students did not perform better than the control group on exams on average, they were less likely to get failing grades or to drop the course. Overall, subgoal labels seemed especially effective for students who might otherwise struggle to pass or complete the course.
Keywords: Worked examples, Subgoal learning, Programming education, Failure rates
Come to my workshop on CS Education at ASEE June 16!
I am attending my first American Society for Engineering Education (ASEE) Conference this year — see the website here: https://www.asee.org/conferences-and-events/conferences/annual-conference/2019.
I’m still figuring out Engineering Education Research, so I’ll be offering a workshop based on our work at Georgia Tech: Techniques for Improved Engagement and Learning of Programming. The workshop is Sunday, June 16, 2019 from 9:00 am to noon. Please come, and please pass this on to others you know who are attending ASEE and might be interested.
Computing education research at Georgia Tech over the last 15 years has led to techniques for teaching programming which improve student learning. Learning is enhanced through greater engagement and reduced cognitive load.
These techniques are:
- Media computation: Teaching programming through manipulation of digital media which improves students’ sense of utility and relevance leading to greater engagement;
- Worked examples: Using worked examples in peer instruction and for prompting for predictions that improve learning;
- Subgoal labeling: Structuring and labeling worked examples to improve immediate learning, retention over time, and transfer to new problems.
The learning objectives for this workshop are for participants to experience these techniques so that they might be able to judge which are most useful for their own practice. Participants will:
- Manipulate digital media with programs that they write during the workshop (laptops required).
- Participate in peer instruction questions using worked examples.
- Compare worked examples with and without subgoal labeling.
How CS differs from other STEM Disciplines: Varying effects of subgoal labeled expository text in programming, chemistry, and statistics
My colleagues Lauren Margulieux and Richard Catrambone (with Laura M. Schaeffer) have a new journal article out that I find fascinating. Lauren, you might recall, was a student of Richard’s who applied subgoal labeling to programming (see the post about her original ICER paper) and worked with Briana Morrison on several experiments that applied subgoal labeling to textual programming and Parson’s problems (see posts on Lauren’s defense and Briana’s).
In this new paper (see link here), they contrast subgoal labels across three different domains: Chemistry, statistics, and computer science (explicitly, programming). I’ve been writing lately about how learning programming differs from learning other STEM disciplines (see this post here, for example). So, I was intrigued to see this paper.
The paper contrasts subgoal labeled expository text (e.g., saying explicitly as a heading Compute Average Frequency) and subgoal labeled worked examples (e.g., saying Compute Average Frequency then showing the equation and the values and the computed result). I’ll jump to the punchline with the table that summarizes the result:

Programming has high complexity. Students learned best when they had both subgoal labeled text and subgoal labeled worked examples. Either one alone didn’t cut it. In Statistics, subgoal labeled examples are pretty important, but the subgoal labeled text doesn’t help much. In Chemistry, both the text and the worked examples improve performance, and there’s a benefit to having both. That’s an argument that Chemistry is more complex than Statistics, but less complex than Programming.
The result is fascinating, for two reasons. First, it gives us a way to empirically order the complexity of learning in these disciplines. Second, it gives us more reason for using subgoal labels in programming instruction — students just won’t learn as well without it.
Graduating Dr. Briana Morrison: Posing New Puzzles for Computing Education Research
I am posting this on the day that I am honored to “hood” Dr. Briana Morrison. “Hooding” is where doctoral candidates are given their academic regalia indicating their doctorate degree. It’s one of those ancient parts of academia that I find really cool. I like the way that the Wikiversity describes it: “The Hooding Ceremony is symbolic of passing the guard from one generation of doctors to the next generation of doctors.”
I’ve written about Briana’s work a lot over the years here:
- Her proposal is described here, “Cognitive Load as a significant problem in Learning Programming.”
- Her first major dissertation accomplishment was developing (with Dr. Brian Dorn) a measurement instrument for cognitive load.
- One of her bigger wins for her dissertation was showing that subgoal labels work for text languages too (ICER 2015).
- Another really significant result was showing that Parson’s Problems were a more sensitive measure of learning than asking students to write code in an assessment, and that subgoal labels make Parson’s Problems better, too.
- She worked a lot with Lauren Margulieux, so many of the links I listed when Dr. Margulieux defended are also relevant for Dr. Morrison.
- At ICER 2016, she presented a replication study of her first given vs. generated subgoals study.
But what I find most interesting about Briana’s dissertation work were the things that didn’t work:
- She tried to show a difference in getting program instruction via audio or text. She didn’t find one. The research on modality effects suggested that she would.
- She tried to show a difference between loop-and-a-half and exit-in-the-middle WHILE loops. Previous studies had found one. She did not.
These kinds of results are so cool to me, because they point out what we don’t know about computing education yet. The prior results and theory were really clear. The study was well-designed and vetted by her committee. The results were contrary to what we expected. WHAT HAPPENED?!? It’s for the next group of researchers to try to figure out.
The most interesting result of that kind in Briana’s dissertation is one that I’ve written about before, but I’d like to pull it all together here because I think that there are some interesting implications of it. To me, this is a Rainfall Problem kind of question.
Here’s the experimental set-up. We’ve got six groups.
- All groups are learning with pairs of a worked example (a completely worked out piece of code) and then a practice problem (maybe a Parson’s Problem, maybe writing some code). We’ll call these WE-P pairs (Worked Example-Practice). Now, some WE-P pairs have the same context (think of it as the story of a story problem), and some have different contexts. Maybe in the same context, you’re asked to compute the average tips for several days of tips as a barista. Maybe in a different context, you compute tips in the worked example, but you compute the average test score in the practice. In general, we predict that different contexts will be harder for the student than having everything the same.
- So we’ve got same context vs different context as one variable we’re manipulating. The other variable is whether the participants get the worked example with NO subgoal labels, or GENERATED subgoal labels, or the participant has to GENERATE subgoal labels. Think of a subgoal label as a comment that explains some code, but it’s the same comment that will appear in several different programs. It’s meant to encourage the student to abstract the meaning of the code.

In the GENERATE condition, the participants get blanks, to encourage them to abstract for themselves. Typically, we’d expect (for research in other parts of STEM with subgoal labels) that GENERATE would lead to more learning than GIVEN labels, but it’s harder. We might get cognitive overload.
In general, GIVEN labels beats out no labels. No problem — that’s what we expect given all the past work on subgoal labels. But when we consider all six groups, we get this picture.

Why would having the same context do worse with GIVEN labels than no labels? Why would the same context do much better with GENERATE labels, but worse when it’s different contexts?
So, Briana, Lauren, and Adrienne Decker replicated the experiment with Adrienne’s students at RIT (ICER 2016). And they found:

The same strange “W” pattern, where we have this odd interaction between context and GIVEN vs. GENERATE that we just don’t have an explanation for.
But here’s the really intriguing part: they also did the experiment with second semester students at RIT. All the weird interactions disappeared! Same context beat different context. GIVEN labels beat GENERATE labels. No labels do the worst. When students get enough experience, they figure things out and behave like students in other parts of STEM.
The puzzle for the community is WHY. Briana has a hypothesis. Novice students don’t attend to the details that they need, unless you change the contexts. Without changing contexts, students even GIVEN labels don’t learn because they’re not paying enough attention. Changing contexts gets them to think, “What’s going on here?” GENERATE is just too hard for novices — the cognitive load of figuring out the code and generating labels is just overwhelming for students, so they do badly when we’d expect them to do better.
Here we have a theory-conflicting result, that has been replicated in two different populations. It’s like the Rainfall Problem. Nobody expected the Rainfall Problem to be hard, but it was. More and more people tried it with their students, and still, it was hard. It took Kathi Fisler to figure out how to teach CS so that most students could succeed at the Rainfall Problem. What could we teach novice CS students so that they avoid the “W” pattern? Is it just time? Will all second semester students avoid the “W”?
Dr. Morrison gave us a really interesting dissertation — some big wins, and some intriguing puzzles for the next researchers to wrestle with. Briana has now joined the computing education research group at U. Nebraska – Omaha, where I expect to see more great results.
Optimizing Learning with Subgoal Labeling: Lauren Margulieux Defends her Dissertation
Lauren Margulieux successfully defended her dissertation Using Subgoal Learning and Self-Explanation to Improve Programming Education in March. Lauren’s been exploring subgoal labeling for improving programming education in a series of fascinating and influential papers. Subgoal labels are inserted into the steps of a worked example to explain the purpose for a set of steps.
- At ICER 2012 (see post here), her paper showed that subgoal labels inserted into App Inventor videos led to improved learning, retention (a week later), and even transfer to new App building problems, all compared to the exact same videos without the subgoal labels. This paper was cited by Rob Moore and his students at MIT in their work developing crowdsourced subgoal labels for videos (see post here).
- At ICER 2015 (see post here), Lauren and Briana Morrison showed that subgoal labels also improved learning for textual programming languages, but the high cognitive load of textual programming language made some forms of subgoal labeling less successful than studies in other disciplines would predict. That paper won the Chairs Award at ICER.
- At SIGCSE 2016 (see post here), Briana presented a paper with Lauren where they showed that subgoal labeling also improved performance on Parson’s Problems.
In her dissertation work, Lauren returned to the challenges of the ICER 2015 paper: Can we make subgoal labeling even more successful? She went back to using App Inventor, to reduce the cognitive load from teaching a textual language.
She compared three different ways of using subgoal labeling.
- In the passive condition, students were just given subgoal labels like in her first experiments.
- In the active condition, students were given a list of subgoal labels. The worked example was segmented into sets of steps that achieved a subgoal, but the label was left blank. Students had to pick the right subgoal label each blank.
- In the constructive condition, students were just given a blank and asked to generate a subgoal label. She had two kinds of constructive conditions. One was “guided” in that there were blanks above sets of steps. The other was “unguided” — just a long list of steps, and she asked students to write labels into margins
Lauren was building on a theory that predicted that the constructive condition would have the best learning, but would also be the hardest. She provided two scaffolds.
- For the conditions where it made sense (i.e., not the passive condition), she provided feedback. She showed half the participants the same worked examples with experimenter labels.
- For half the constructive participants, the label wasn’t blank. Instead there was a hint. All the steps that achieved the same subgoal were labeled “Label 1,” and all the steps that achieved a different subgoal were labelled “Label 2,” and so on.
Here’s the big “interesting/surprising” graph from her dissertation.

As predicted, constructive was better than active or passive. What’s interesting is that the very best performance was guided constructive without hints but with feedback AND with hints but without feedback. Now that’s weird. Why would having more support (both hints and feedback) lead to worse performance?
There are several possible hypotheses for these results, and Lauren pursued one of these one step further. Maybe students developed their own cognitive model when they constructed their own labels with hints, and seeing the feedback (experimenter’s labels) created some kind of dissonance or conflict. Without hints, maybe the feedback helped them make sense of the worked example.
Lauren ran one more experiment where she contrasted getting scaffolding with the experimenter’s labels versus getting scaffolding with the student’s labels (put in all the right places in the worked example). Students who were scaffolded with their own labels performed better on later problem solving than those who were scaffolded with experimenter labels. Students scaffolded with experimenter labels did not perform better than those who did not receive any scaffolding at all. Her results support this hypothesis — the experimenter’s labels can get in the way of the understanding that the students are building.

There are several implications from Lauren’s dissertation. One is that we can do even better than just giving students labels — getting them to write them themselves is even better for learning. Feedback isn’t the most critical part of the learning when subgoal labeling, which is surprising and fascinating. Constructive subgoal labeling lends itself to an online implementation, which is the direction Lauren that is explicitly exploring. How do we build effective programming education online?
Lauren has accepted an Assistant Professor position in the Learning Technologies Division at Georgia State University. I’m so glad for her, and even happier that she’s nearby so that we can continue collaborating!
Cognitive Load as a Significant Problem in Learning Programming: Briana Morrison’s Dissertation Proposal
Briana Morrison is defending her proposal today. One chapter of her work is based on her ICER 2015 paper that won the Chairs Award for best paper (see post here). Good luck, Briana!
Title: Replicating Experiments from Educational Psychology to Develop Insights into Computing Education: Cognitive Load as a Significant Problem in Learning Programming
Briana Morrison
Ph.D. student
Human Centered Computing
College of Computing
Georgia Institute of Technology
Date: Wednesday, November 11, 2015
Time: 2 PM to 4 PM EDT
Location: TSRB 223
Committee
————–
Dr. Mark Guzdial, School of Interactive Computing (advisor)
Dr. Betsy DiSalvo, School of Interactive Computing
Dr. Wendy Newstetter, School of Interactive Computing
Dr. Richard Catrambone, School of Psychology
Dr. Beth Simon, Jacobs School of Engineering at University of California San Diego and Principal Teaching and Learning Specialist, Coursera
Abstract
———–
Students often find learning to program difficult. This may be because the concepts are inherently difficult due to the fact that the elements of learning to program are highly interconnected. Instructors may be able to lower the complexity of learning to program by designing instructional materials that use educational psychology principles.
The overarching goal of this research is to gain more understanding and insight into the optimal conditions under which learning programming can be successful which is defined as students being able to apply their acquired knowledge and skills in new or familiar problem-solving situations. Cognitive load theory (CLT), and its associated effects, describe the role of the learner’s memory during the learning process. By minimizing undesirable loads within the instructional materials the learner’s memory can hold more relevant information, thereby improving the effectiveness of the learning process.
This proposal uses cognitive load theory to improve learning in programming. First an instrument for measuring cognitive load components within introductory programming was developed and initially validated. We have explored reducing the cognitive load by changing the modality in which students receive the learning material. This had no effect on novices’ retention of knowledge or their ability to transfer knowledge. We then attempted to reduce the cognitive load by adding subgoal labels to the instructional material. This had some effect on the learning gains under some conditions. Students who learned using subgoal labels demonstrated higher learning gains than the other conditions on the programming assessment task. We also explored using a low cognitive load assessment task, a Parsons problem, to measure learning gains. This low cognitive load assessment task proved more sensitive than the open ended programming assessment tasks in capturing student learning. Students who were given subgoal labels regardless of context transfer condition out performed those in the other conditions.
In my final, proposed study I change how we teach a programming construct through its format and content in order to reduce cognitive load. The changed construct is presumed to be a more natural cognitive fit for students based on previous research.
The Bigger Issues in Learning to Code: Culture and Pedagogy
I mentioned in a previous blog post the nice summary article that Audrey Watters wrote (linked below) about Learning to Code trends in educational technology in 2012, when I critiqued Jeff Atwood’s position on not learning to code.
Audrey does an excellent job of describing the big trends in learning to code this last year, from CodeAcademy to Bret Victor and Khan Academy and MOOCs. But the part that I liked the best was where she identified the problem that cool technology and badges won’t solve: culture and pedagogy.
This is a problem. A big problem. A problem that an interactive JavaScript lesson with badges won’t solve.
Two organizations — Black Girls Code and CodeNow — did hold successful Kickstarter campaigns this year to help “change the ratio” and give young kids of color and young girls opportunities to learn programming. And the Irish non-profit CoderDojo also ventured state-side in 2012, helping expand afterschool opportunities for kids interested in hacking. The Maker Movement another key ed-tech trend this year is also opening doors for folks to play and experiment with technologies.
And yet, despite all the hype and hullaballoo from online learning startups and their marketing campaigns that now “everyone can learn to code,” its clear there are still plenty of problems with the culture and the pedagogy surrounding computer science education.
via Top Ed-Tech Trends of 2012: Learning to Code | Inside Higher Ed.
We still do need new programming languages whose design is informed by how humans work and learn. We still do need new learning technologies that can help us provide the right learning opportunities for individual student’s needs and can provide access to those who might not otherwise get the opportunity. But those needs are swamped by culture and pedagogy.
What do I mean by culture and pedagogy?
Culture: Betsy diSalvo’s work on Glitch is a great example of considering culture in computing education. I’ve written about her work before — that she engaged a couple dozen African-American teen men in computing, by hiring them to be video game testers, and the majority of those students went on to post-secondary education in computing. I’ve talked with Betsy several times about how and why that worked. The number one reason why it worked: Betsy spent the time to understand the African-American teen men’s values, their culture, what they thought was important. She engaged in an iterative design process with groups of teen men to figure out what would most appeal to them, how she could reframe computing into something that they would engage with. Betsy taught coding — but in a different way, in a different context, with different values, where the way, context, and values were specifically tuned to her audience. Is it worth that effort? Yeah, because it’s about making a computing that appeals to these other audiences.
Pedagogy: A lot of my work these days is about pedagogy. I use peer instruction in my classrooms, and try out worked examples in various ways. In our research, we use subgoal labels to improve our instructional materials. These things really work.
Let me give you an example with graphs that weren’t in Lauren Margelieux’s paper, but are in the talk slides that she made for me. As you may recall, we had two sets of instructional materials: A set of nice videos and text descriptions that Barbara Ericson built, and a similar set with subgoal labels inserted. We found that the subgoal labelled instruction led to better performance (faster and more correct) immediately after instruction, more retention (better performance a week later), and better performance on a transfer task (got more done on a new app that the students had never seen before). But I hadn’t shown you before just how enormous was the gap between the subgoal labelled group and the conventional group on the transfer task.
Part of the transfer task involved defining a variable in App Inventor — don’t just grab a component, but define a variable to represent that component. The subgoal label group did that more often. ALOT more often.

Lauren also noticed that the conventional group tended to “thrash,” to pull out more blocks in App Inventor than they actually needed. The correlation between number of blocks drawn out and correctness was r = -.349 — you are less likely to be correct (by a large amount) if you pull out extra blocks. Here’s the graph of number of blocks pulled out by each group.
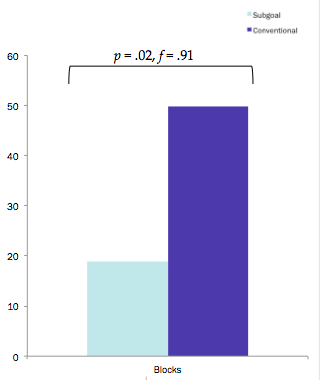
These aren’t small differences! These are huge differences from a surprisingly small difference between the instructional materials. Improving our pedagogy could have a huge impact.
I agree with Audrey: Culture and pedagogy are two of the bigger issues in learning to code.

Recent Comments